URL
A Uniform Resource Locator (URL), colloquially termed a web address,[1] is a reference to a web resource that specifies its location on a computer network and a mechanism for retrieving it. A URL is a specific type of Uniform Resource Identifier (URI),[2][3] although many people use the two terms interchangeably.[4][lower-alpha 1] Thus http://www.example.com is a URL, while www.example.com is not.[6]</ref> URLs occur most commonly to reference web pages (http), but are also used for file transfer (ftp), email (mailto), database access (JDBC), and many other applications.
| Status | Published |
|---|---|
| First published | 1994 |
| Latest version | URL Living Standard |
| Organization | Internet Engineering Task Force (IETF) |
| Committee | Web Hypertext Application Technology Working Group (WHATWG) |
| Editors | Anne van Kesteren |
| Authors | Tim Berners-Lee |
| Base standards | RFC 3986. – Uniform Resource Identifier (URI): Generic Syntax. RFC 4248. – The telnet URI Scheme. |
| Related standards | URI , URN |
| Domain | World Wide Web |
| License | CC BY 4.0 |
| Abbreviation | URL |
| Website | https://url.spec.whatwg.org |
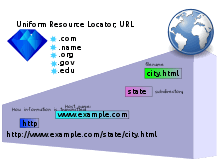
Most web browsers display the URL of a web page above the page in an address bar. A typical URL could have the form http://www.example.com/index.html, which indicates a protocol (http), a hostname (www.example.com), and a file name (index.html).
History
Uniform Resource Locators were defined in RFC 1738 in 1994 by Tim Berners-Lee, the inventor of the World Wide Web, and the URI working group of the Internet Engineering Task Force (IETF),[7] as an outcome of collaboration started at the IETF Living Documents birds of a feather session in 1992.[8][9]
The format combines the pre-existing system of domain names (created in 1985) with file path syntax, where slashes are used to separate directory and filenames. Conventions already existed where server names could be prefixed to complete file paths, preceded by a double slash (//).[10]
Berners-Lee later expressed regret at the use of dots to separate the parts of the domain name within URIs, wishing he had used slashes throughout,[10] and also said that, given the colon following the first component of a URI, the two slashes before the domain name were unnecessary.[11]
An early (1993) draft of the HTML Specification[12] referred to "Universal" Resource Locators. This was dropped some time between June 1994 (RFC 1630) and October 1994 (draft-ietf-uri-url-08.txt).[13]
Syntax
Every HTTP URL conforms to the syntax of a generic URI. The URI generic syntax consists of a hierarchical sequence of five components:[14]
URI = scheme:[//authority]path[?query][#fragment]
where the authority component divides into three subcomponents:
authority = [userinfo@]host[:port]
This is represented in a syntax diagram as:

The URI comprises:
- A non-empty scheme component followed by a colon (
:), consisting of a sequence of characters beginning with a letter and followed by any combination of letters, digits, plus (+), period (.), or hyphen (-). Although schemes are case-insensitive, the canonical form is lowercase and documents that specify schemes must do so with lowercase letters. Examples of popular schemes includehttp,https,ftp,mailto,file,data, andirc. URI schemes should be registered with the Internet Assigned Numbers Authority (IANA), although non-registered schemes are used in practice.[lower-alpha 2] - An optional component preceded by two slashes (
//), comprising:- An optional userinfo subcomponent that may consist of a user name and an optional password preceded by a colon (
:), followed by an at symbol (@). Use of the formatusername:passwordin the userinfo subcomponent is deprecated for security reasons. Applications should not render as clear text any data after the first colon (:) found within a userinfo subcomponent unless the data after the colon is the empty string (indicating no password). - A host subcomponent, consisting of either a registered name (including but not limited to a hostname), or an IP address. IPv4 addresses must be in dot-decimal notation, and IPv6 addresses must be enclosed in brackets (
[]).[16][lower-alpha 3] - An optional port subcomponent preceded by a colon (
:).
- An optional userinfo subcomponent that may consist of a user name and an optional password preceded by a colon (
- A path component, consisting of a sequence of path segments separated by a slash (
/). A path is always defined for a URI, though the defined path may be empty (zero length). A segment may also be empty, resulting in two consecutive slashes (//) in the path component. A path component may resemble or map exactly to a file system path, but does not always imply a relation to one. If an authority component is present, then the path component must either be empty or begin with a slash (/). If an authority component is absent, then the path cannot begin with an empty segment, that is with two slashes (//), as the following characters would be interpreted as an authority component.[18] The final segment of the path may be referred to as a 'slug'.
| Query delimiter | Example |
|---|---|
Ampersand (&) |
key1=value1&key2=value2 |
Semicolon (;)[lower-alpha 4] |
key1=value1;key2=value2 |
- An optional query component preceded by a question mark (
?), containing a query string of non-hierarchical data. Its syntax is not well defined, but by convention is most often a sequence of attribute–value pairs separated by a delimiter. - An optional fragment component preceded by a hash (
#). The fragment contains a fragment identifier providing direction to a secondary resource, such as a section heading in an article identified by the remainder of the URI. When the primary resource is an HTML document, the fragment is often anidattribute of a specific element, and web browsers will scroll this element into view.
A web browser will usually dereference a URL by performing an HTTP request to the specified host, by default on port number 80. URLs using the https scheme require that requests and responses be made over a secure connection to the website.
Internationalized URL
Internet users are distributed throughout the world using a wide variety of languages and alphabets and expect to be able to create URLs in their own local alphabets. An Internationalized Resource Identifier (IRI) is a form of URL that includes Unicode characters. All modern browsers support IRIs. The parts of the URL requiring special treatment for different alphabets are the domain name and path.[20][21]
The domain name in the IRI is known as an Internationalized Domain Name (IDN). Web and Internet software automatically convert the domain name into punycode usable by the Domain Name System; for example, the Chinese URL http://例子.卷筒纸 becomes http://xn--fsqu00a.xn--3lr804guic/. The xn-- indicates that the character was not originally ASCII.[22]
The URL path name can also be specified by the user in the local writing system. If not already encoded, it is converted to UTF-8, and any characters not part of the basic URL character set are escaped as hexadecimal using percent-encoding; for example, the Japanese URL http://example.com/引き割り.html becomes http://example.com/%E5%BC%95%E3%81%8D%E5%89%B2%E3%82%8A.html. The target computer decodes the address and displays the page.[20]
Protocol-relative URLs
Protocol-relative links (PRL), also known as protocol-relative URLs (PRURL), are URLs that have no protocol specified. For example, //example.com will use the protocol of the current page, typically HTTP or HTTPS.[23][24]
See also
- PURL - Persistent URL
- CURIE (Compact URI)
- Fragment identifier
- Internet Resource Locator (IRL)
- Internationalized resource identifier (IRI)
- Semantic URL
- Typosquatting
- Uniform Resource Identifier
- URL normalization
- Use of slashes in networking
Notes
- A URL implies the means to access an indicated resource and is denoted by a protocol or an access mechanism, which is not true of every URI.[5]<ref name='FOOTNOTEJoint W3C/IETF URI Planning Interest Group2002'>Joint W3C/IETF URI Planning Interest Group (2002).
- The procedures for registering new URI schemes were originally defined in 1999 by RFC 2717, and are now defined by RFC 7595, published in June 2015.[15]
- For URIs relating to resources on the World Wide Web, some web browsers allow
.0portions of dot-decimal notation to be dropped or raw integer IP addresses to be used.[17] - Historic RFC 1866 (obsoleted by RFC 2854) encourages CGI authors to support ';' in addition to '&'.[19]
Citations
- W3C (2009).
- "Forward and Backslashes in URLs". zzz.buzz. Retrieved 2018-09-19.
- RFC 3986 (2005).
- Joint W3C/IETF URI Planning Interest Group (2002).
- RFC 2396 (1998).
- Miessler, Daniel. "The Difference Between URLs and URIs".
- W3C (1994).
- IETF (1992).
- Berners-Lee (1994).
- Berners-Lee (2000).
- BBC News (2009).
- Berners-Lee, Tim; Connolly, Daniel "Dan" (March 1993). Hypertext Markup Language (draft RFCxxx) (Technical report). p. 28.
- Berners-Lee, Tim; Masinter, Larry; McCahill, Mark Perry (October 1994). Uniform Resource Locators (URL) (Technical report). cited in Ang, C. S.; Martin, D. C. (January 1995). Constituent Component Interface++ (Technical report). UCSF Library and Center for Knowledge Management.
- RFC 3986, section 3 (2005).
- IETF (2015).
- RFC 3986 (2005), §3.2.2.
- Lawrence (2014).
- RFC 2396 (1998), §3.3.
- RFC 1866 (1995), §8.2.1.
- W3C (2008).
- W3C (2014).
- IANA (2003).
- Glaser, J. D. (2013). Secure Development for Mobile Apps: How to Design and Code Secure Mobile Applications with PHP and JavaScript. CRC Press. p. 193. ISBN 978-1-48220903-7. Retrieved 2015-10-12.
- Schafer, Steven M. (2011). HTML, XHTML, and CSS Bible. John Wiley & Sons. p. 124. ISBN 978-1-11808130-3. Retrieved 2015-10-12.
References
- "Berners-Lee "sorry" for slashes". BBC News. 2009-10-14. Retrieved 2010-02-14.
- "Living Documents BoF Minutes". World Wide Web Consortium. 1992-03-18. Retrieved 2011-12-26.
- Berners-Lee, Tim (1994-03-21). "Uniform Resource Locators (URL): A Syntax for the Expression of Access Information of Objects on the Network". World Wide Web Consortium. Retrieved 2015-09-13.
- Berners-Lee, Tim; Masinter, Larry; McCahill, Mark Perry (August 1998). Uniform Resource Locators (URL). doi:10.17487/RFC1738. RFC 1738. Retrieved 2015-08-31.
- Berners-Lee, Tim (2015) [2000]. "Why the //, #, etc?". Frequently asked questions. World Wide Web Consortium. Retrieved 2010-02-03.
- Connolly, Daniel "Dan"; Sperberg-McQueen, C. Michael, eds. (2009-05-21). "Web addresses in HTML 5". World Wide Web Consortium. Retrieved 2015-09-13.
- Internet Assigned Numbers Authority (2003-02-14). "Completion of IANA Selection of IDNA Prefix". IETF-Announce mailing list. Archived from the original on 2004-12-08. Retrieved 2015-09-03.
- Berners-Lee, Tim; Fielding, Roy T.; Masinter, Larry (August 1998). Uniform Resource Identifiers (URI): Generic Syntax. doi:10.17487/RFC2396. RFC 2396. Retrieved 2015-08-31.
- Hansen, Tony; Hardie, Ted (June 2015). Thaler, Dave (ed.). Guidelines and Registration Procedures for URI Schemes. doi:10.17487/RFC7595. RFC 7595.
- Mealling, Michael; Denenberg, Ray, eds. (August 2002). Report from the Joint W3C/IETF URI Planning Interest Group: Uniform Resource Identifiers (URIs), URLs, and Uniform Resource Names (URNs): Clarifications and Recommendations. doi:10.17487/RFC3305. RFC 3305. Retrieved 2015-09-13.
- Berners-Lee, Tim; Fielding, Roy T.; Masinter, Larry (January 2005). Uniform Resource Identifiers (URI): Generic Syntax. doi:10.17487/RFC3986. RFC 3986. Retrieved 2015-08-31.
- "An Introduction to Multilingual Web Addresses". 2008-05-09. Retrieved 2015-01-11.
- Phillip, A. (2014). "What is Happening with "International URLs"". World Wide Web Consortium. Retrieved 2015-01-11.
- Lawrence, Eric. "Browser Arcana: IP Literals in URLs". docs.microsoft.com. Archived from the original on 2020-06-22. Retrieved 2020-06-22.
External links
| Authority control |
|
|---|