Restriction site associated DNA markers
Restriction site associated DNA (RAD) markers are a type of genetic marker which are useful for association mapping, QTL-mapping, population genetics, ecological genetics and evolution. The use of RAD markers for genetic mapping is often called RAD mapping. An important aspect of RAD markers and mapping is the process of isolating RAD tags, which are the DNA sequences that immediately flank each instance of a particular restriction site of a restriction enzyme throughout the genome.[1] Once RAD tags have been isolated, they can be used to identify and genotype DNA sequence polymorphisms mainly in form of single nucleotide polymorphisms (SNPs).[1] Polymorphisms that are identified and genotyped by isolating and analyzing RAD tags are referred to as RAD markers.
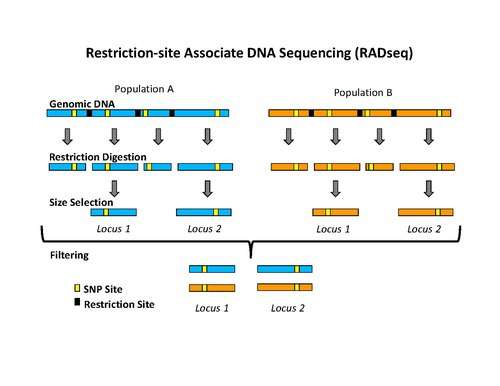
Isolation of RAD tags
The use of the flanking DNA sequences around each restriction site is an important aspect of RAD tags.[1] The density of RAD tags in a genome depends on the restriction enzyme used during the isolation process.[2] There are other restriction site marker techniques, like RFLP or amplified fragment length polymorphism (AFLP), which use fragment length polymorphism caused by different restriction sites, for the distinction of genetic polymorphism. The use of the flanking DNA-sequences in RAD tag techniques is referred as reduced-representation method.[3]
The initial procedure to isolate RAD tags involved digesting DNA with a particular restriction enzyme, ligating biotinylated adapters to the overhangs, randomly shearing the DNA into fragments much smaller than the average distance between restriction sites, and isolating the biotinylated fragments using streptavidin beads.[1] This procedure was used initially to isolate RAD tags for microarray analysis.[1][4][5] More recently, the RAD tag isolation procedure has been modified for use with high-throughput sequencing on the Illumina platform, which has the benefit of greatly reduced raw error rates and high throughput.[2] The new procedure involves digesting DNA with a particular restriction enzyme (for example: SbfI, NsiI,…), ligating the first adapter, called P1, to the overhangs, randomly shearing the DNA into fragments much smaller than the average distance between restriction sites, preparing the sheared ends into blunt ends and ligating the second adapter (P2), and using PCR to specifically amplify fragments that contain both adapters. Importantly, the first adapter contains a short DNA sequence barcode, called MID (molecular identifier) that is used as a marker to identify different DNA samples that are pooled together and sequenced in the same reaction.[2][6] The use of high-throughput sequencing to analyze RAD tags can be classified as reduced-representation sequencing, which includes, among other things, RADSeq (RAD-Sequencing).[3]
Detection and genotyping of RAD markers
Once RAD tags have been isolated, they can be used to identify and genotype DNA sequence polymorphisms such as single nucleotide polymorphisms (SNPs).[1][2] These polymorphic sites are referred to as RAD markers. The most efficient way to find RAD tags is by high-throughput DNA sequencing,[2][6] called RAD tag sequencing, RAD sequencing, RAD-Seq, or RADSeq.
Prior to the development of high-throughput sequencing technologies, RAD markers were identified by hybridizing RAD tags to microarrays.[1][4][5] Due to the low sensitivity of microarrays, this approach can only detect either DNA sequence polymorphisms that disrupt restriction sites and lead to the absence of RAD tags or substantial DNA sequence polymorphisms that disrupt RAD tag hybridization. Therefore, the genetic marker density that can be achieved with microarrays is much lower than what is possible with high-throughput DNA-sequencing.[7]
History
RAD markers were first implemented using microarrays and later adapted for NGS (Next-Generation-Sequencing).[7] It was developed jointly by Eric Johnson and William Cresko's laboratories at the University of Oregon around 2006. They confirmed the utility of RAD markers by identifying recombination breakpoints in D. melanogaster and by detecting QTLs in threespine sticklebacks.[1]
In 2012, scientists published a modified RAD tagging method called double digest RADseq.[8] They added a second restriction enzyme and a tight DNA size selection step to perform low-cost population genotyping.
Sources
- Miller MR; Dunham JP; Amores A; Cresko WA; Johnson EA (2007). "Rapid and cost-effective polymorphism identification and genotyping using restriction site associated DNA (RAD) markers". Genome Research. 17 (2): 240–248. doi:10.1101/gr.5681207. PMC 1781356. PMID 17189378.
- Baird NA; Etter PD; Atwood TS; Currey MC; Shiver AL; Lewis ZA; Selker EU; Cresko WA; Johnson EA (2008). "Rapid SNP discovery and genetic mapping using sequenced RAD markers". PLOS ONE. 3 (10): e3376. doi:10.1371/journal.pone.0003376.
- Davey JW; Hohenlohe PA; Etter PD; Boone JQ; Catchen JM; Blaxter ML (2011). "Genome-wide genetic marker discovery and genotyping using next-generation sequencing". Nature Reviews Genetics. 12: 499–510. doi:10.1038/nrg3012. PMID 21681211.
- Miller MR; Atwood TS; Eames BF; Eberhart JK; Yan YL; Postlethwait JH; Johnson EA (2007). "RAD marker microarrays enable rapid mapping of zebrafish mutations". Genome Biol. 8 (6): R105. doi:10.1186/gb-2007-8-6-r105.
- Lewis ZA; Shiver AL; Stiffler N; Miller MR; Johnson EA; Selker EU (2007). "High density detection of restriction site associated DNA (RAD) markers for rapid mapping of mutated loci in Neurospora". Genetics. 177 (2): 1163–1171. doi:10.1534/genetics.107.078147. PMC 2034621. PMID 17660537.
- Hohenlohe PA; Bassham S; Etter PD; Stiffler N; Johnson EA; Cresko WA (2010). "Population genomics of parallel adaptation in threespine stickleback using sequenced RAD tags". PLoS Genetics. 6 (2): e1000862. doi:10.1371/journal.pgen.1000862. PMC 2829049. PMID 20195501.
- Shendure J; Ji H (2008). "Next-generation DNA-sequencing". Nature Biotechnology. 26: 1135–1145. doi:10.1038/nbt1486. PMID 18846087.
- Hohenlohe PA; Bassham S; Etter PD; Stiffler N; Johnson EA; Cresko WA (2012). "Population Genomics of Parallel Adaptation in Threespine Stickleback using Sequenced RAD Tags". PLOS ONE. 7: e37135. doi:10.1371/journal.pone.0037135. PMC 3365034. PMID 22675423.