Preconditioner
In mathematics, preconditioning is the application of a transformation, called the preconditioner, that conditions a given problem into a form that is more suitable for numerical solving methods. Preconditioning is typically related to reducing a condition number of the problem. The preconditioned problem is then usually solved by an iterative method.
Preconditioning for linear systems
In linear algebra and numerical analysis, a preconditioner of a matrix is a matrix such that has a smaller condition number than . It is also common to call the preconditioner, rather than , since itself is rarely explicitly available. In modern preconditioning, the application of , i.e., multiplication of a column vector, or a block of column vectors, by , is commonly performed by rather sophisticated computer software packages in a matrix-free fashion, i.e., where neither , nor (and often not even ) are explicitly available in a matrix form.




Preconditioners are useful in iterative methods to solve a linear system for since the rate of convergence for most iterative linear solvers increases because the condition number of a matrix decreases as a result of preconditioning. Preconditioned iterative solvers typically outperform direct solvers, e.g., Gaussian elimination, for large, especially for sparse, matrices. Iterative solvers can be used as matrix-free methods, i.e. become the only choice if the coefficient matrix is not stored explicitly, but is accessed by evaluating matrix-vector products.


Description
Instead of solving the original linear system above, one may solve the right preconditioned system:

via solving

for and


for .
Alternatively, one may solve the left preconditioned system:

Both systems give the same solution as the original system as long as the preconditioner matrix is nonsingular. The left preconditioning is more common.
The goal of this preconditioned system is to reduce the condition number of the left or right preconditioned system matrix or respectively. The preconditioned matrix or is almost never explicitly formed. Only the action of applying the preconditioner solve operation to a given vector need to be computed in iterative methods.



Typically there is a trade-off in the choice of . Since the operator must be applied at each step of the iterative linear solver, it should have a small cost (computing time) of applying the operation. The cheapest preconditioner would therefore be since then Clearly, this results in the original linear system and the preconditioner does nothing. At the other extreme, the choice gives which has optimal condition number of 1, requiring a single iteration for convergence; however in this case and applying the preconditioner is as difficult as solving the original system. One therefore chooses as somewhere between these two extremes, in an attempt to achieve a minimal number of linear iterations while keeping the operator as simple as possible. Some examples of typical preconditioning approaches are detailed below.





Preconditioned iterative methods
Preconditioned iterative methods for are, in most cases, mathematically equivalent to standard iterative methods applied to the preconditioned system For example, the standard Richardson iteration for solving is


Applied to the preconditioned system it turns into a preconditioned method


Examples of popular preconditioned iterative methods for linear systems include the preconditioned conjugate gradient method, the biconjugate gradient method, and generalized minimal residual method. Iterative methods, which use scalar products to compute the iterative parameters, require corresponding changes in the scalar product together with substituting for


Linear preconditioning
Let a linear iterative method be given by the matrix splitting , and iteration matrix .


Assume the following
- the system matrix is symmetric positive-definite
- the splitting matrix is symmetric positive-definite
- the linear iterative method is convergent: .


Then, the reduction of the system's condition number can be bounded from above by


Geometric interpretation
For a symmetric positive definite matrix the preconditioner is typically chosen to be symmetric positive definite as well. The preconditioned operator is then also symmetric positive definite, but with respect to the -based scalar product. In this case, the desired effect in applying a preconditioner is to make the quadratic form of the preconditioned operator with respect to the -based scalar product to be nearly spherical.[1]
Variable and non-linear preconditioning
Denoting , we highlight that preconditioning is practically implemented as multiplying some vector by , i.e., computing the product In many applications, is not given as a matrix, but rather as an operator acting on the vector . Some popular preconditioners, however, change with and the dependence on may not be linear. Typical examples involve using non-linear iterative methods, e.g., the conjugate gradient method, as a part of the preconditioner construction. Such preconditioners may be practically very efficient, however, their behavior is hard to predict theoretically.




Spectrally equivalent preconditioning
The most common use of preconditioning is for iterative solution of linear systems resulting from approximations of partial differential equations. The better the approximation quality, the larger the matrix size is. In such a case, the goal of optimal preconditioning is, on the one side, to make the spectral condition number of to be bounded from above by a constant independent of the matrix size, which is called spectrally equivalent preconditioning by D'yakonov. On the other hand, the cost of application of the should ideally be proportional (also independent of the matrix size) to the cost of multiplication of by a vector.
Examples
Jacobi (or diagonal) preconditioner
The Jacobi preconditioner is one of the simplest forms of preconditioning, in which the preconditioner is chosen to be the diagonal of the matrix Assuming , we get It is efficient for diagonally dominant matrices .



SPAI
The Sparse Approximate Inverse preconditioner minimises where is the Frobenius norm and is from some suitably constrained set of sparse matrices. Under the Frobenius norm, this reduces to solving numerous independent least-squares problems (one for every column). The entries in must be restricted to some sparsity pattern or the problem remains as difficult and time-consuming as finding the exact inverse of . The method was introduced by M.J. Grote and T. Huckle together with an approach to selecting sparsity patterns.[2]


Other preconditioners
External links
Preconditioning for eigenvalue problems
Eigenvalue problems can be framed in several alternative ways, each leading to its own preconditioning. The traditional preconditioning is based on the so-called spectral transformations. Knowing (approximately) the targeted eigenvalue, one can compute the corresponding eigenvector by solving the related homogeneous linear system, thus allowing to use preconditioning for linear system. Finally, formulating the eigenvalue problem as optimization of the Rayleigh quotient brings preconditioned optimization techniques to the scene.[3]
Spectral transformations
By analogy with linear systems, for an eigenvalue problem one may be tempted to replace the matrix with the matrix using a preconditioner . However, this makes sense only if the seeking eigenvectors of and are the same. This is the case for spectral transformations.

The most popular spectral transformation is the so-called shift-and-invert transformation, where for a given scalar , called the shift, the original eigenvalue problem is replaced with the shift-and-invert problem . The eigenvectors are preserved, and one can solve the shift-and-invert problem by an iterative solver, e.g., the power iteration. This gives the Inverse iteration, which normally converges to the eigenvector, corresponding to the eigenvalue closest to the shift . The Rayleigh quotient iteration is a shift-and-invert method with a variable shift.


Spectral transformations are specific for eigenvalue problems and have no analogs for linear systems. They require accurate numerical calculation of the transformation involved, which becomes the main bottleneck for large problems.
General preconditioning
To make a close connection to linear systems, let us suppose that the targeted eigenvalue is known (approximately). Then one can compute the corresponding eigenvector from the homogeneous linear system . Using the concept of left preconditioning for linear systems, we obtain , where is the preconditioner, which we can try to solve using the Richardson iteration




The ideal preconditioning[3]
The Moore–Penrose pseudoinverse is the preconditioner, which makes the Richardson iteration above converge in one step with , since , denoted by , is the orthogonal projector on the eigenspace, corresponding to . The choice is impractical for three independent reasons. First, is actually not known, although it can be replaced with its approximation . Second, the exact Moore–Penrose pseudoinverse requires the knowledge of the eigenvector, which we are trying to find. This can be somewhat circumvented by the use of the Jacobi–Davidson preconditioner , where approximates . Last, but not least, this approach requires accurate numerical solution of linear system with the system matrix , which becomes as expensive for large problems as the shift-and-invert method above. If the solution is not accurate enough, step two may be redundant.








Practical preconditioning
Let us first replace the theoretical value in the Richardson iteration above with its current approximation to obtain a practical algorithm


A popular choice is using the Rayleigh quotient function . Practical preconditioning may be as trivial as just using or For some classes of eigenvalue problems the efficiency of has been demonstrated, both numerically and theoretically. The choice allows one to easily utilize for eigenvalue problems the vast variety of preconditioners developed for linear systems.





Due to the changing value , a comprehensive theoretical convergence analysis is much more difficult, compared to the linear systems case, even for the simplest methods, such as the Richardson iteration.
Preconditioning in optimization
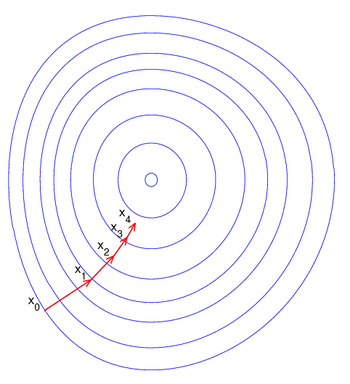
In optimization, preconditioning is typically used to accelerate first-order optimization algorithms.
Description
For example, to find a local minimum of a real-valued function using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point:



The preconditioner is applied to the gradient:

Preconditioning here can be viewed as changing the geometry of the vector space with the goal to make the level sets look like circles.[4] In this case the preconditioned gradient aims closer to the point of the extrema as on the figure, which speeds up the convergence.
Connection to linear systems
The minimum of a quadratic function
- ,

where and are real column-vectors and is a real symmetric positive-definite matrix, is exactly the solution of the linear equation . Since , the preconditioned gradient descent method of minimizing is




This is the preconditioned Richardson iteration for solving a system of linear equations.
Connection to eigenvalue problems
The minimum of the Rayleigh quotient

where is a real non-zero column-vector and is a real symmetric positive-definite matrix, is the smallest eigenvalue of , while the minimizer is the corresponding eigenvector. Since is proportional to , the preconditioned gradient descent method of minimizing is




This is an analog of preconditioned Richardson iteration for solving eigenvalue problems.
Variable preconditioning
In many cases, it may be beneficial to change the preconditioner at some or even every step of an iterative algorithm in order to accommodate for a changing shape of the level sets, as in

One should have in mind, however, that constructing an efficient preconditioner is very often computationally expensive. The increased cost of updating the preconditioner can easily override the positive effect of faster convergence.
References
- Shewchuk, Jonathan Richard (August 4, 1994). "An Introduction to the Conjugate Gradient Method Without the Agonizing Pain" (PDF).
- Grote, M. J. & Huckle, T. (1997). "Parallel Preconditioning with Sparse Approximate Inverses". SIAM Journal on Scientific Computing. 18 (3): 838–53. doi:10.1137/S1064827594276552.
- Knyazev, Andrew V. (1998). "Preconditioned eigensolvers - an oxymoron?". Electronic Transactions on Numerical Analysis. 7: 104–123.
- Himmelblau, David M. (1972). Applied Nonlinear Programming. New York: McGraw-Hill. pp. 78–83. ISBN 0-07-028921-2.
Sources
- Axelsson, Owe (1996). Iterative Solution Methods. Cambridge University Press. p. 6722. ISBN 978-0-521-55569-2.
- D'yakonov, E. G. (1996). Optimization in solving elliptic problems. CRC-Press. p. 592. ISBN 978-0-8493-2872-5.
- Saad, Yousef & van der Vorst, Henk (2001). "Iterative solution of linear systems in the 20th century". In Brezinski, C. & Wuytack, L. (eds.). Numerical Analysis: Historical Developments in the 20th Century. Elsevier Science Publishers. §8 Preconditioning methods, pp 193–8. ISBN 0-444-50617-9.
- van der Vorst, H. A. (2003). Iterative Krylov Methods for Large Linear systems. Cambridge University Press, Cambridge. ISBN 0-521-81828-1.