Conjugate gradient method
In mathematics, the conjugate gradient method is an algorithm for the numerical solution of particular systems of linear equations, namely those whose matrix is symmetric and positive-definite. The conjugate gradient method is often implemented as an iterative algorithm, applicable to sparse systems that are too large to be handled by a direct implementation or other direct methods such as the Cholesky decomposition. Large sparse systems often arise when numerically solving partial differential equations or optimization problems.
The conjugate gradient method can also be used to solve unconstrained optimization problems such as energy minimization. It was mainly developed by Magnus Hestenes and Eduard Stiefel,[1][2] who programmed it on the Z4.[3]
The biconjugate gradient method provides a generalization to non-symmetric matrices. Various nonlinear conjugate gradient methods seek minima of nonlinear equations.
Description of the problem addressed by conjugate gradients
Suppose we want to solve the system of linear equations

for the vector x, where the known n × n matrix A is symmetric (i.e., AT = A), positive-definite (i.e. xTAx > 0 for all non-zero vectors x in Rn), and real, and b is known as well. We denote the unique solution of this system by .

As a direct method
We say that two non-zero vectors u and v are conjugate (with respect to A) if

Since A is symmetric and positive-definite, the left-hand side defines an inner product

Two vectors are conjugate if and only if they are orthogonal with respect to this inner product. Being conjugate is a symmetric relation: if u is conjugate to v, then v is conjugate to u. Suppose that

is a set of n mutually conjugate vectors (with respect to A). Then P forms a basis for , and we may express the solution x∗ of in this basis:



Based on this expansion we calculate:

Left-multiplying by :


substituting and :



then and using yields



which implies

This gives the following method for solving the equation Ax = b: find a sequence of n conjugate directions, and then compute the coefficients αk.
As an iterative method
If we choose the conjugate vectors pk carefully, then we may not need all of them to obtain a good approximation to the solution x∗. So, we want to regard the conjugate gradient method as an iterative method. This also allows us to approximately solve systems where n is so large that the direct method would take too much time.
We denote the initial guess for x∗ by x0 (we can assume without loss of generality that x0 = 0, otherwise consider the system Az = b − Ax0 instead). Starting with x0 we search for the solution and in each iteration we need a metric to tell us whether we are closer to the solution x∗ (that is unknown to us). This metric comes from the fact that the solution x∗ is also the unique minimizer of the following quadratic function

The existence of a unique minimizer is apparent as its second derivative is given by a symmetric positive-definite matrix

and that the minimizer (use Df(x)=0) solves the initial problem is obvious from its first derivative

This suggests taking the first basis vector p0 to be the negative of the gradient of f at x = x0. The gradient of f equals Ax − b. Starting with an initial guess x0, this means we take p0 = b − Ax0. The other vectors in the basis will be conjugate to the gradient, hence the name conjugate gradient method. Note that p0 is also the residual provided by this initial step of the algorithm.
Let rk be the residual at the kth step:

As observed above, rk is the negative gradient of f at x = xk, so the gradient descent method would require to move in the direction rk. Here, however, we insist that the directions pk be conjugate to each other. A practical way to enforce this, is by requiring that the next search direction be built out of the current residual and all previous search directions.[4] This gives the following expression:

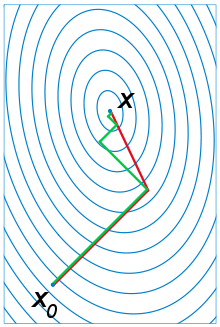
(see the picture at the top of the article for the effect of the conjugacy constraint on convergence). Following this direction, the next optimal location is given by

with

where the last equality follows from the definition of rk . The expression for can be derived if one substitutes the expression for xk+1 into f and minimizing it w.r.t.


The resulting algorithm
The above algorithm gives the most straightforward explanation of the conjugate gradient method. Seemingly, the algorithm as stated requires storage of all previous searching directions and residue vectors, as well as many matrix-vector multiplications, and thus can be computationally expensive. However, a closer analysis of the algorithm shows that ri is orthogonal to rj , i.e. , for i ≠ j. And pi is A-orthogonal to pj , i.e. , for i ≠ j. This can be regarded that as the algorithm progresses, pi and ri span the same Krylov subspace. Where ri form the orthogonal basis with respect to standard inner product, and pi form the orthogonal basis with respect to inner product induced by A. Therefore, xk can be regarded as the projection of x on the Krylov subspace.


The algorithm is detailed below for solving Ax = b where A is a real, symmetric, positive-definite matrix. The input vector x0 can be an approximate initial solution or 0. It is a different formulation of the exact procedure described above.

This is the most commonly used algorithm. The same formula for βk is also used in the Fletcher–Reeves nonlinear conjugate gradient method.
Computation of alpha and beta
In the algorithm, αk is chosen such that is orthogonal to rk. The denominator is simplified from


since . The βk is chosen such that is conjugated to pk. Initially, βk is



using

and equivalently

the numerator of βk is rewritten as

because and rk are orthogonal by design. The denominator is rewritten as

using that the search directions pk are conjugated and again that the residuals are orthogonal. This gives the β in the algorithm after cancelling αk.
Example code in MATLAB / GNU Octave
function x = conjgrad(A, b, x)
r = b - A * x;
p = r;
rsold = r' * r;
for i = 1:length(b)
Ap = A * p;
alpha = rsold / (p' * Ap);
x = x + alpha * p;
r = r - alpha * Ap;
rsnew = r' * r;
if sqrt(rsnew) < 1e-10
break;
end
p = r + (rsnew / rsold) * p;
rsold = rsnew;
end
end
Numerical example
Consider the linear system Ax = b given by

we will perform two steps of the conjugate gradient method beginning with the initial guess

in order to find an approximate solution to the system.
Solution
For reference, the exact solution is

Our first step is to calculate the residual vector r0 associated with x0. This residual is computed from the formula r0 = b - Ax0, and in our case is equal to

Since this is the first iteration, we will use the residual vector r0 as our initial search direction p0; the method of selecting pk will change in further iterations.
We now compute the scalar α0 using the relationship

We can now compute x1 using the formula

This result completes the first iteration, the result being an "improved" approximate solution to the system, x1. We may now move on and compute the next residual vector r1 using the formula

Our next step in the process is to compute the scalar β0 that will eventually be used to determine the next search direction p1.

Now, using this scalar β0, we can compute the next search direction p1 using the relationship

We now compute the scalar α1 using our newly acquired p1 using the same method as that used for α0.

Finally, we find x2 using the same method as that used to find x1.

The result, x2, is a "better" approximation to the system's solution than x1 and x0. If exact arithmetic were to be used in this example instead of limited-precision, then the exact solution would theoretically have been reached after n = 2 iterations (n being the order of the system).
Convergence properties
The conjugate gradient method can theoretically be viewed as a direct method, as it produces the exact solution after a finite number of iterations, which is not larger than the size of the matrix, in the absence of round-off error. However, the conjugate gradient method is unstable with respect to even small perturbations, e.g., most directions are not in practice conjugate, and the exact solution is never obtained. Fortunately, the conjugate gradient method can be used as an iterative method as it provides monotonically improving approximations to the exact solution, which may reach the required tolerance after a relatively small (compared to the problem size) number of iterations. The improvement is typically linear and its speed is determined by the condition number of the system matrix : the larger is, the slower the improvement.[5]



If is large, preconditioning is used to replace the original system with such that is smaller than , see below.




Convergence theorem
Define a subset of polynomials as

where is the set of polynomials of maximal degree .


Let be the iterative approximations of the exact solution , and define the errors as . Now, the rate of convergence can be approximated as [6]



where denotes the spectrum, and denotes the condition number.

Note, the important limit when tends to


This limit shows a faster convergence rate compared to the iterative methods of Jacobi or Gauss–Seidel which scale as .

The preconditioned conjugate gradient method
In most cases, preconditioning is necessary to ensure fast convergence of the conjugate gradient method. The preconditioned conjugate gradient method takes the following form [7]:
- repeat
- if rk+1 is sufficiently small then exit loop end if
- end repeat
- The result is xk+1











The above formulation is equivalent to applying the conjugate gradient method without preconditioning to the system[1]

where

The preconditioner matrix M has to be symmetric positive-definite and fixed, i.e., cannot change from iteration to iteration. If any of these assumptions on the preconditioner is violated, the behavior of the preconditioned conjugate gradient method may become unpredictable.
An example of a commonly used preconditioner is the incomplete Cholesky factorization.
The flexible preconditioned conjugate gradient method
In numerically challenging applications, sophisticated preconditioners are used, which may lead to variable preconditioning, changing between iterations. Even if the preconditioner is symmetric positive-definite on every iteration, the fact that it may change makes the arguments above invalid, and in practical tests leads to a significant slow down of the convergence of the algorithm presented above. Using the Polak–Ribière formula

instead of the Fletcher–Reeves formula
may dramatically improve the convergence in this case.[8] This version of the preconditioned conjugate gradient method can be called[9] flexible, as it allows for variable preconditioning. The flexible version is also shown[10] to be robust even if the preconditioner is not symmetric positive definite (SPD).
The implementation of the flexible version requires storing an extra vector. For a fixed SPD preconditioner, so both formulas for βk are equivalent in exact arithmetic, i.e., without the round-off error.

The mathematical explanation of the better convergence behavior of the method with the Polak–Ribière formula is that the method is locally optimal in this case, in particular, it does not converge slower than the locally optimal steepest descent method.[11]
Example code in MATLAB / GNU Octave
function [x, k] = cgp(x0, A, C, b, mit, stol, bbA, bbC)
% Synopsis:
% x0: initial point
% A: Matrix A of the system Ax=b
% C: Preconditioning Matrix can be left or right
% mit: Maximum number of iterations
% stol: residue norm tolerance
% bbA: Black Box that computes the matrix-vector product for A * u
% bbC: Black Box that computes:
% for left-side preconditioner : ha = C \ ra
% for right-side preconditioner: ha = C * ra
% x: Estimated solution point
% k: Number of iterations done
%
% Example:
% tic;[x, t] = cgp(x0, S, speye(1), b, 3000, 10^-8, @(Z, o) Z*o, @(Z, o) o);toc
% Elapsed time is 0.550190 seconds.
%
% Reference:
% Métodos iterativos tipo Krylov para sistema lineales
% B. Molina y M. Raydan - {{ISBN|908-261-078-X}}
if nargin < 8, error('Not enough input arguments. Try help.'); end;
if isempty(A), error('Input matrix A must not be empty.'); end;
if isempty(C), error('Input preconditioner matrix C must not be empty.'); end;
x = x0;
ha = 0;
hp = 0;
hpp = 0;
ra = 0;
rp = 0;
rpp = 0;
u = 0;
k = 0;
ra = b - bbA(A, x0); % <--- ra = b - A * x0;
while norm(ra, inf) > stol
ha = bbC(C, ra); % <--- ha = C \ ra;
k = k + 1;
if (k == mit), warning('GCP:MAXIT', 'mit reached, no conversion.'); return; end;
hpp = hp;
rpp = rp;
hp = ha;
rp = ra;
t = rp' * hp;
if k == 1
u = hp;
else
u = hp + (t / (rpp' * hpp)) * u;
end;
Au = bbA(A, u); % <--- Au = A * u;
a = t / (u' * Au);
x = x + a * u;
ra = rp - a * Au;
end;
Vs. the locally optimal steepest descent method
In both the original and the preconditioned conjugate gradient methods one only needs to set in order to make them locally optimal, using the line search, steepest descent methods. With this substitution, vectors p are always the same as vectors z, so there is no need to store vectors p. Thus, every iteration of these steepest descent methods is a bit cheaper compared to that for the conjugate gradient methods. However, the latter converge faster, unless a (highly) variable and/or non-SPD preconditioner is used, see above.

Derivation of the method
The conjugate gradient method can be derived from several different perspectives, including specialization of the conjugate direction method for optimization, and variation of the Arnoldi/Lanczos iteration for eigenvalue problems. Despite differences in their approaches, these derivations share a common topic—proving the orthogonality of the residuals and conjugacy of the search directions. These two properties are crucial to developing the well-known succinct formulation of the method.
The conjugate gradient method can also be derived using optimal control theory.[12] In this approach, the conjugate gradient method falls out as an optimal feedback controller,

for the double integrator system,

The quantities and are variable feedback gains.[12]


Conjugate gradient on the normal equations
The conjugate gradient method can be applied to an arbitrary n-by-m matrix by applying it to normal equations ATA and right-hand side vector ATb, since ATA is a symmetric positive-semidefinite matrix for any A. The result is conjugate gradient on the normal equations (CGNR).
- ATAx = ATb
As an iterative method, it is not necessary to form ATA explicitly in memory but only to perform the matrix-vector and transpose matrix-vector multiplications. Therefore, CGNR is particularly useful when A is a sparse matrix since these operations are usually extremely efficient. However the downside of forming the normal equations is that the condition number κ(ATA) is equal to κ2(A) and so the rate of convergence of CGNR may be slow and the quality of the approximate solution may be sensitive to roundoff errors. Finding a good preconditioner is often an important part of using the CGNR method.
Several algorithms have been proposed (e.g., CGLS, LSQR). The LSQR algorithm purportedly has the best numerical stability when A is ill-conditioned, i.e., A has a large condition number.
See also
- Biconjugate gradient method (BiCG)
- Conjugate residual method
- Gaussian belief propagation
- Iterative method: Linear systems
- Krylov subspace
- Nonlinear conjugate gradient method
- Preconditioning
- Sparse matrix-vector multiplication
References
- Hestenes, Magnus R.; Stiefel, Eduard (December 1952). "Methods of Conjugate Gradients for Solving Linear Systems". Journal of Research of the National Bureau of Standards. 49 (6): 409. doi:10.6028/jres.049.044.
- Straeter, T. A. "On the Extension of the Davidon-Broyden Class of Rank One, Quasi-Newton Minimization Methods to an Infinite Dimensional Hilbert Space with Applications to Optimal Control Problems". NASA Technical Reports Server. NASA. hdl:2060/19710026200.
- Speiser, Ambros "Konrad Zuse and the ERMETH: A worldwide comparison of architectures" ("Konrad Zuse und die ERMETH: Ein weltweiter Architektur-Vergleich"), in: Hans Dieter Hellige (ed.): Geschichten der Informatik. Visionen, Paradigmen, Leitmotive. Berlin, Springer 2004, ISBN 3-540-00217-0. p. 185.
- The conjugation constraint is an orthonormal-type constraint and hence the algorithm bears resemblance to Gram-Schmidt orthonormalization.
- Saad, Yousef (2003). Iterative methods for sparse linear systems (2nd ed.). Philadelphia, Pa.: Society for Industrial and Applied Mathematics. pp. 195. ISBN 978-0-89871-534-7.
- Hackbusch, W. (2016-06-21). Iterative solution of large sparse systems of equations (2nd ed.). Switzerland: Springer. ISBN 9783319284835. OCLC 952572240.
- Barrett, Richard; Berry, Michael; Chan, Tony F.; Demmel, James; Donato, June; Dongarra, Jack; Eijkhout, Victor; Pozo, Roldan; Romine, Charles; van der Vorst, Henk. Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods (PDF) (2nd ed.). Philadelphia, PA: SIAM. p. 13. Retrieved 2020-03-31.
- Golub, Gene H.; Ye, Qiang (1999). "Inexact Preconditioned Conjugate Gradient Method with Inner-Outer Iteration". SIAM Journal on Scientific Computing. 21 (4): 1305. CiteSeerX 10.1.1.56.1755. doi:10.1137/S1064827597323415.
- Notay, Yvan (2000). "Flexible Conjugate Gradients". SIAM Journal on Scientific Computing. 22 (4): 1444–1460. CiteSeerX 10.1.1.35.7473. doi:10.1137/S1064827599362314.
- Henricus Bouwmeester, Andrew Dougherty, Andrew V Knyazev. Nonsymmetric Preconditioning for Conjugate Gradient and Steepest Descent Methods. Procedia Computer Science, Volume 51, Pages 276-285, Elsevier, 2015. https://doi.org/10.1016/j.procs.2015.05.241
- Knyazev, Andrew V.; Lashuk, Ilya (2008). "Steepest Descent and Conjugate Gradient Methods with Variable Preconditioning". SIAM Journal on Matrix Analysis and Applications. 29 (4): 1267. arXiv:math/0605767. doi:10.1137/060675290.
- Ross, I. M., "An Optimal Control Theory for Accelerated Optimization," arXiv:1902.09004, 2019.
Further reading
- Atkinson, Kendell A. (1988). "Section 8.9". An introduction to numerical analysis (2nd ed.). John Wiley and Sons. ISBN 978-0-471-50023-0.
- Avriel, Mordecai (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 978-0-486-43227-4.
- Golub, Gene H.; Van Loan, Charles F. (1996-10-15). "Chapter 10". Matrix computations (3rd ed.). Johns Hopkins University Press. ISBN 978-0-8018-5414-9.
- Saad, Yousef (2003-04-01). "Chapter 6". Iterative methods for sparse linear systems (2nd ed.). SIAM. ISBN 978-0-89871-534-7.
External links
- "Conjugate gradients, method of", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
| Authority control |
|
|---|