Oblivious data structure
In computer science, an oblivious data structure is a data structure that gives no information about the sequence or pattern of the operations that have been applied except for the final result of the operations.[1]
In most conditions, even if the data is encrypted, the access pattern can be achieved, and this pattern can leak some important information such as encryption keys. And in the outsourcing of cloud data, this leakage of access pattern is still very serious. An access pattern is a specification of an access mode for every attribute of a relation schema. For example, the sequences of user read or write the data in the cloud are access patterns.
We say if a machine is oblivious if the sequence in which it accesses is equivalent for any two input with the same running time. So the data access pattern is independent from the input.
Applications:
- Cloud data outsourcing: When writing or reading data from a cloud server, oblivious data structures are useful. And modern database rely on data structure heavily, so oblivious data structure come in handy.
- Secure processor: Tamper-resilient secure processors are used for defense against physical attacks or the malicious intruders access the users’ computer platforms. The existing secure processors designed in academia and industry include AEGIS and Intel SGX encrypt. But the memory addresses are still transferred in the clear on the memory bus. So the research finds that this memory buses can give out the information about encryption keys. With the Oblivious data structure comes in practical, the secure processor can obfuscate memory access pattern in a provably secure manner.
- Secure computation: Traditionally people used circuit-model to do the secure computation, but the model is not enough for the security when the amount of data is getting big. RAM-model secure computation was proposed as an alternative to the traditional circuit model, and oblivious data structure is used to prevent information access behavioral being stolen.
Oblivious Data Structures
Oblivious RAM
Goldreich and Ostrovsky proposed this term on software protection.
The memory access of oblivious RAM is probabilistic and the probabilistic distribution is independent of the input. In the paper composed by Goldreich and Ostrovsky have theorem to oblivious RAM: Let RAM(m) denote a RAM with m memory locations and access to a random oracle machine. Then t steps of an arbitrary RAM(m) program can be simulated by less than steps of an oblivious . Every oblivious simulation of RAM(m) must make at least accesses in order to simulate t steps.



Now we have the square-root algorithm to simulate the oblivious ram working.
- For each accesses, randomly permute first memory.
- Check the shelter words first if we want to access a word.
- If the word is there, access one of the dummy words. And if the word is not there, find the permuted location.


To access original RAM in t steps we need to simulate it with steps for the oblivious RAM. For each access, the cost would be O().


Another way to simulate is hierarchical algorithm. The basic idea is to consider the shelter memory as a buffer, and extend it to the multiple levels of buffers. For level I, there are buckets and for each bucket has log t items. For each level there is a random selected hash function.

The operation is like the following: At first load program to the last level, which can be say has buckets. For reading, check the bucket from each level, If (V,X) is already found, pick a bucket randomly to access, and if it is not found, check the bucket , there is only one real match and remaining are dummy entries . For writing, put (V,X) to the first level, and if the first I levels are full, move all I levels to levels and empty the first I levels.



The time cost for each level cost O(log t); cost for every access is ; The cost of Hashing is .


Oblivious Tree
An Oblivious Tree is a rooted tree with the following property:
- All the leaves are in the same level.
- All the internal nodes have degree at most 3.
- Only the nodes along the rightmost path in the tree may have degree of one.
The oblivious tree is a data structure similar to 2-3 Tree, but with the additional property of being oblivious. The rightmost path may have degree one and this can help to describe the update algorithms. Oblivious tree requires randomization to achieve a running time for the update operations. And for two sequences of operations M and N acting to the tree, the output of the tree has the same output probability distributions. For the tree, there are three operations:

CREATE (L)- build a new tree storing the sequence of values L at its leaves.
INSERT (b, i,T)- insert a new leaf node storing the value b as the ith leaf of the tree T.
DELETE (i, T)- remove the ith leaf from T.
Step of Create: The list of nodes at the ithlevel is obtained traversing the list of nodes at level i+1 from left to right and repeatedly doing the following:
- Choose d {2, 3} uniformly at random.
- If there are less than d nodes left at level i+1, set d equal to the number of nodes left.
- Create a new node n at level I with the next d nodes at level i+1 as children and compute the size of n as the sum of the sizes of its children.
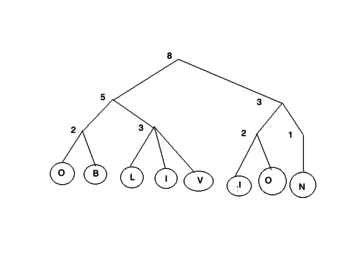 oblivious tree
oblivious tree
For example, if the coin tosses of d {2, 3} has an outcome of: 2, 3, 2, 2, 2, 2, 3 stores the string “OBLIVION” as follow oblivious tree.
Both the INSERT (b, I, T) and DELETE(I, T) have the O(log n) expected running time. And for INSERT and DELETE
we have:
INSERT (b, I, CREATE (L)) = CREATE (L [1] + …….., L[ i], b, L[i+1]………..) DELETE (I, CREATE (L)) = CREATE (L[1]+ ………L[I - 1], L[i+1], ………..)
For example, if the CREATE (ABCDEFG) or INSERT (C, 2, CREATE (ABDEFG)) is run, it yields the same probabilities of out come between these two operations.
References
- Xiao Wang, Kartik Nayak, Chang Liu, Hubert Chan, Elaine Shi, Emil Stefanov and Yan Huang. Oblivious Data Structures. Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security
- Daniele Micciancio. Oblivious Data Structure: Application to Cryptography.
- Oded Goldreich. Software Protection and Simulation on Oblivious RAM. TR-93-072, November, 1993.
- John C. Mitchell and Joe Zimmerman. Data-Oblivious Data Structures. Department of Computer Science, Stanford University, Stanford, US.
- Craig Gentry, Kenny A. Goldman, Shai Halevi, Charanjit S. Jutla, Mariana Raykova, and Daniel Wichs. Optimizing ORAM and using it efficiently for secure computation. In Emiliano De Cristofaro and Matthew Wright, editors, Privacy Enhancing Technologies, volume 7981 of Lecture Notes in Computer Science, pages 1–18. Springer, 2013