Multivariate kernel density estimation
Kernel density estimation is a nonparametric technique for density estimation i.e., estimation of probability density functions, which is one of the fundamental questions in statistics. It can be viewed as a generalisation of histogram density estimation with improved statistical properties. Apart from histograms, other types of density estimators include parametric, spline, wavelet and Fourier series. Kernel density estimators were first introduced in the scientific literature for univariate data in the 1950s and 1960s[1][2] and subsequently have been widely adopted. It was soon recognised that analogous estimators for multivariate data would be an important addition to multivariate statistics. Based on research carried out in the 1990s and 2000s, multivariate kernel density estimation has reached a level of maturity comparable to its univariate counterparts.[3]
Motivation
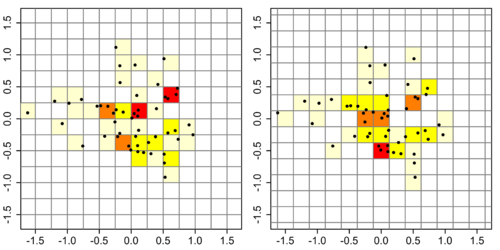
We take an illustrative synthetic bivariate data set of 50 points to illustrate the construction of histograms. This requires the choice of an anchor point (the lower left corner of the histogram grid). For the histogram on the left, we choose (−1.5, −1.5): for the one on the right, we shift the anchor point by 0.125 in both directions to (−1.625, −1.625). Both histograms have a binwidth of 0.5, so any differences are due to the change in the anchor point only. The colour-coding indicates the number of data points which fall into a bin: 0=white, 1=pale yellow, 2=bright yellow, 3=orange, 4=red. The left histogram appears to indicate that the upper half has a higher density than the lower half, whereas the reverse is the case for the right-hand histogram, confirming that histograms are highly sensitive to the placement of the anchor point.[4]
One possible solution to this anchor point placement problem is to remove the histogram binning grid completely. In the left figure below, a kernel (represented by the grey lines) is centred at each of the 50 data points above. The result of summing these kernels is given on the right figure, which is a kernel density estimate. The most striking difference between kernel density estimates and histograms is that the former are easier to interpret since they do not contain artifices induced by a binning grid. The coloured contours correspond to the smallest region which contains the respective probability mass: red = 25%, orange + red = 50%, yellow + orange + red = 75%, thus indicating that a single central region contains the highest density.
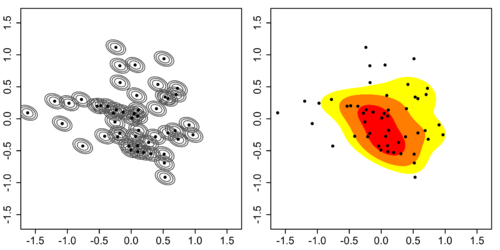
The goal of density estimation is to take a finite sample of data and to make inferences about the underlying probability density function everywhere, including where no data are observed. In kernel density estimation, the contribution of each data point is smoothed out from a single point into a region of space surrounding it. Aggregating the individually smoothed contributions gives an overall picture of the structure of the data and its density function. In the details to follow, we show that this approach leads to a reasonable estimate of the underlying density function.
Definition
The previous figure is a graphical representation of kernel density estimate, which we now define in an exact manner. Let x1, x2, ..., xn be a sample of d-variate random vectors drawn from a common distribution described by the density function ƒ. The kernel density estimate is defined to be

where
- x = (x1, x2, …, xd)T, xi = (xi1, xi2, …, xid)T, i = 1, 2, …, n are d-vectors;
- H is the bandwidth (or smoothing) d×d matrix which is symmetric and positive definite;
- K is the kernel function which is a symmetric multivariate density;
- .

The choice of the kernel function K is not crucial to the accuracy of kernel density estimators, so we use the standard multivariate normal kernel throughout: , where H plays the role of the covariance matrix. On the other hand, the choice of the bandwidth matrix H is the single most important factor affecting its accuracy since it controls the amount and orientation of smoothing induced.[5]:36–39 That the bandwidth matrix also induces an orientation is a basic difference between multivariate kernel density estimation from its univariate analogue since orientation is not defined for 1D kernels. This leads to the choice of the parametrisation of this bandwidth matrix. The three main parametrisation classes (in increasing order of complexity) are S, the class of positive scalars times the identity matrix; D, diagonal matrices with positive entries on the main diagonal; and F, symmetric positive definite matrices. The S class kernels have the same amount of smoothing applied in all coordinate directions, D kernels allow different amounts of smoothing in each of the coordinates, and F kernels allow arbitrary amounts and orientation of the smoothing. Historically S and D kernels are the most widespread due to computational reasons, but research indicates that important gains in accuracy can be obtained using the more general F class kernels.[6][7]


Optimal bandwidth matrix selection
The most commonly used optimality criterion for selecting a bandwidth matrix is the MISE or mean integrated squared error

This in general does not possess a closed-form expression, so it is usual to use its asymptotic approximation (AMISE) as a proxy

where
- , with R(K) = (4π)−d/2 when K is a normal kernel
- ,


- with Id being the d × d identity matrix, with m2 = 1 for the normal kernel
- D2ƒ is the d × d Hessian matrix of second order partial derivatives of ƒ
- is a d2 × d2 matrix of integrated fourth order partial derivatives of ƒ
- vec is the vector operator which stacks the columns of a matrix into a single vector e.g.


The quality of the AMISE approximation to the MISE[5]:97 is given by

where o indicates the usual small o notation. Heuristically this statement implies that the AMISE is a 'good' approximation of the MISE as the sample size n → ∞.
It can be shown that any reasonable bandwidth selector H has H = O(n−2/(d+4)) where the big O notation is applied elementwise. Substituting this into the MISE formula yields that the optimal MISE is O(n−4/(d+4)).[5]:99–100 Thus as n → ∞, the MISE → 0, i.e. the kernel density estimate converges in mean square and thus also in probability to the true density f. These modes of convergence are confirmation of the statement in the motivation section that kernel methods lead to reasonable density estimators. An ideal optimal bandwidth selector is

Since this ideal selector contains the unknown density function ƒ, it cannot be used directly. The many different varieties of data-based bandwidth selectors arise from the different estimators of the AMISE. We concentrate on two classes of selectors which have been shown to be the most widely applicable in practice: smoothed cross validation and plug-in selectors.
Plug-in
The plug-in (PI) estimate of the AMISE is formed by replacing Ψ4 by its estimator


where . Thus is the plug-in selector.[8][9] These references also contain algorithms on optimal estimation of the pilot bandwidth matrix G and establish that converges in probability to HAMISE.



Smoothed cross validation
Smoothed cross validation (SCV) is a subset of a larger class of cross validation techniques. The SCV estimator differs from the plug-in estimator in the second term

Thus is the SCV selector.[9][10] These references also contain algorithms on optimal estimation of the pilot bandwidth matrix G and establish that converges in probability to HAMISE.


Rule of thumb
Silverman's rule of thumb suggests using where is the standard deviation of the ith variable and . Scott's rule is .




Asymptotic analysis
In the optimal bandwidth selection section, we introduced the MISE. Its construction relies on the expected value and the variance of the density estimator[5]:97

where * is the convolution operator between two functions, and

For these two expressions to be well-defined, we require that all elements of H tend to 0 and that n−1 |H|−1/2 tends to 0 as n tends to infinity. Assuming these two conditions, we see that the expected value tends to the true density f i.e. the kernel density estimator is asymptotically unbiased; and that the variance tends to zero. Using the standard mean squared value decomposition

we have that the MSE tends to 0, implying that the kernel density estimator is (mean square) consistent and hence converges in probability to the true density f. The rate of convergence of the MSE to 0 is the necessarily the same as the MISE rate noted previously O(n−4/(d+4)), hence the covergence rate of the density estimator to f is Op(n−2/(d+4)) where Op denotes order in probability. This establishes pointwise convergence. The functional covergence is established similarly by considering the behaviour of the MISE, and noting that under sufficient regularity, integration does not affect the convergence rates.
For the data-based bandwidth selectors considered, the target is the AMISE bandwidth matrix. We say that a data-based selector converges to the AMISE selector at relative rate Op(n−α), α > 0 if

It has been established that the plug-in and smoothed cross validation selectors (given a single pilot bandwidth G) both converge at a relative rate of Op(n−2/(d+6)) [9][11] i.e., both these data-based selectors are consistent estimators.
Density estimation with a full bandwidth matrix
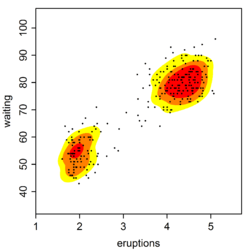
The ks package[12] in R implements the plug-in and smoothed cross validation selectors (amongst others). This dataset (included in the base distribution of R) contains 272 records with two measurements each: the duration time of an eruption (minutes) and the waiting time until the next eruption (minutes) of the Old Faithful Geyser in Yellowstone National Park, USA.
The code fragment computes the kernel density estimate with the plug-in bandwidth matrix Again, the coloured contours correspond to the smallest region which contains the respective probability mass: red = 25%, orange + red = 50%, yellow + orange + red = 75%. To compute the SCV selector, Hpi is replaced with Hscv. This is not displayed here since it is mostly similar to the plug-in estimate for this example.

library(ks)
data(faithful)
H <- Hpi(x=faithful)
fhat <- kde(x=faithful, H=H)
plot(fhat, display="filled.contour2")
points(faithful, cex=0.5, pch=16)
Density estimation with a diagonal bandwidth matrix
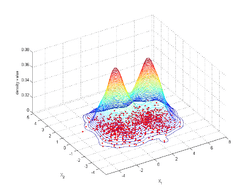
We consider estimating the density of the Gaussian mixture (4π)−1 exp(−1⁄2 (x12 + x22)) + (4π)−1 exp(−1⁄2 ((x1 - 3.5)2 + x22)), from 500 randomly generated points. We employ the Matlab routine for 2-dimensional data. The routine is an automatic bandwidth selection method specifically designed for a second order Gaussian kernel.[13] The figure shows the joint density estimate that results from using the automatically selected bandwidth.
Matlab script for the example
Type the following commands in Matlab after downloading and saving the function kde2d.m in the current directory.
clear all
% generate synthetic data
data=[randn(500,2);
randn(500,1)+3.5, randn(500,1);];
% call the routine, which has been saved in the current directory
[bandwidth,density,X,Y]=kde2d(data);
% plot the data and the density estimate
contour3(X,Y,density,50), hold on
plot(data(:,1),data(:,2),'r.','MarkerSize',5)
Alternative optimality criteria
The MISE is the expected integrated L2 distance between the density estimate and the true density function f. It is the most widely used, mostly due to its tractability and most software implement MISE-based bandwidth selectors. There are alternative optimality criteria, which attempt to cover cases where MISE is not an appropriate measure.[3]:34–37,78 The equivalent L1 measure, Mean Integrated Absolute Error, is

Its mathematical analysis is considerably more difficult than the MISE ones. In practice, the gain appears not to be significant.[14] The L∞ norm is the Mean Uniform Absolute Error

which has been investigated only briefly.[15] Likelihood error criteria include those based on the Mean Kullback–Leibler divergence

and the Mean Hellinger distance

The KL can be estimated using a cross-validation method, although KL cross-validation selectors can be sub-optimal even if it remains consistent for bounded density functions.[16] MH selectors have been briefly examined in the literature.[17]
All these optimality criteria are distance based measures, and do not always correspond to more intuitive notions of closeness, so more visual criteria have been developed in response to this concern.[18]
Objective and data-driven kernel selection
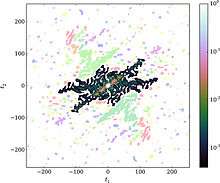



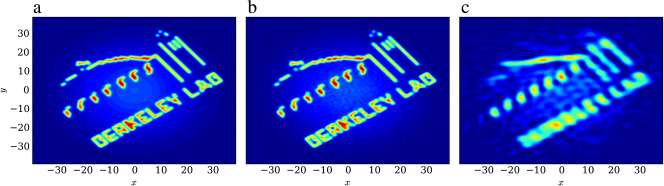
Recent research has shown that the kernel and its bandwidth can both be optimally and objectively chosen from the input data itself without making any assumptions about the form of the distribution.[19] The resulting kernel density estimate converges rapidly to the true probability distribution as samples are added: at a rate close to the expected for parametric estimators.[19][20][21] This kernel estimator works for univariate and multivariate samples alike. The optimal kernel is defined in Fourier space—as the optimal damping function (the Fourier transform of the kernel )-- in terms of the Fourier transform of the data , the empirical characteristic function (see Kernel density estimation):






where, N is the number of data points, d is the number of dimensions (variables), and is a filter that is equal to 1 for 'accepted frequencies' and 0 otherwise. There are various ways to define this filter function, and a simple one that works for univariate or multivariate samples is called the 'lowest contiguous hypervolume filter'; is chosen such that the only accepted frequencies are a contiguous subset of frequencies surrounding the origin for which (see [21] for a discussion of this and other filter functions).

Note that direct calculation of the empirical characteristic function (ECF) is slow, since it essentially involves a direct Fourier transform of the data samples. However, it has been found that the ECF can be approximated accurately using a non-uniform fast Fourier transform (nuFFT) method,[20][21] which increases the calculation speed by several orders of magnitude (depending on the dimensionality of the problem). The combination of this objective KDE method and the nuFFT-based ECF approximation has been referred to as fastKDE in the literature.[21]
See also
- Kernel density estimation – univariate kernel density estimation.
- Variable kernel density estimation – estimation of multivariate densities using the kernel with variable bandwidth
References
- Rosenblatt, M. (1956). "Remarks on some nonparametric estimates of a density function". Annals of Mathematical Statistics. 27 (3): 832–837. doi:10.1214/aoms/1177728190.
- Parzen, E. (1962). "On estimation of a probability density function and mode". Annals of Mathematical Statistics. 33 (3): 1065–1076. doi:10.1214/aoms/1177704472.
- Simonoff, J.S. (1996). Smoothing Methods in Statistics. Springer. ISBN 978-0-387-94716-7.
- Silverman, B.W. (1986). Density Estimation for Statistics and Data Analysis. Chapman & Hall/CRC. pp. 7–11. ISBN 978-0-412-24620-3.
- Wand, M.P; Jones, M.C. (1995). Kernel Smoothing. London: Chapman & Hall/CRC. ISBN 978-0-412-55270-0.
- Wand, M.P.; Jones, M.C. (1993). "Comparison of smoothing parameterizations in bivariate kernel density estimation". Journal of the American Statistical Association. 88 (422): 520–528. doi:10.1080/01621459.1993.10476303. JSTOR 2290332.
- Duong, T.; Hazelton, M.L. (2003). "Plug-in bandwidth matrices for bivariate kernel density estimation". Journal of Nonparametric Statistics. 15: 17–30. doi:10.1080/10485250306039.
- Wand, M.P.; Jones, M.C. (1994). "Multivariate plug-in bandwidth selection". Computational Statistics. 9: 97–177.
- Duong, T.; Hazelton, M.L. (2005). "Cross validation bandwidth matrices for multivariate kernel density estimation". Scandinavian Journal of Statistics. 32 (3): 485–506. doi:10.1111/j.1467-9469.2005.00445.x.
- Hall, P.; Marron, J.; Park, B. (1992). "Smoothed cross-validation". Probability Theory and Related Fields. 92: 1–20. doi:10.1007/BF01205233.
- Duong, T.; Hazelton, M.L. (2005). "Convergence rates for unconstrained bandwidth matrix selectors in multivariate kernel density estimation". Journal of Multivariate Analysis. 93 (2): 417–433. doi:10.1016/j.jmva.2004.04.004.
- Duong, T. (2007). "ks: Kernel density estimation and kernel discriminant analysis in R". Journal of Statistical Software. 21 (7). doi:10.18637/jss.v021.i07.
- Botev, Z.I.; Grotowski, J.F.; Kroese, D.P. (2010). "Kernel density estimation via diffusion". Annals of Statistics. 38 (5): 2916–2957. arXiv:1011.2602. doi:10.1214/10-AOS799.
- Hall, P.; Wand, M.P. (1988). "Minimizing L1 distance in nonparametric density estimation". Journal of Multivariate Analysis. 26: 59–88. doi:10.1016/0047-259X(88)90073-5.
- Cao, R.; Cuevas, A.; Manteiga, W.G. (1994). "A comparative study of several smoothing methods in density estimation". Computational Statistics and Data Analysis. 17 (2): 153–176. doi:10.1016/0167-9473(92)00066-Z.
- Hall, P. (1989). "On Kullback-Leibler loss and density estimation". Annals of Statistics. 15 (4): 589–605. doi:10.1214/aos/1176350606.
- Ahmad, I.A.; Mugdadi, A.R. (2006). "Weighted Hellinger distance as an error criterion for bandwidth selection in kernel estimation". Journal of Nonparametric Statistics. 18 (2): 215–226. doi:10.1080/10485250600712008.
- Marron, J.S.; Tsybakov, A. (1996). "Visual error criteria for qualitative smoothing". Journal of the American Statistical Association. 90 (430): 499–507. doi:10.2307/2291060. JSTOR 2291060.
- Bernacchia, Alberto; Pigolotti, Simone (2011-06-01). "Self-consistent method for density estimation". Journal of the Royal Statistical Society, Series B. 73 (3): 407–422. arXiv:0908.3856. doi:10.1111/j.1467-9868.2011.00772.x. ISSN 1467-9868.
- O’Brien, Travis A.; Collins, William D.; Rauscher, Sara A.; Ringler, Todd D. (2014-11-01). "Reducing the computational cost of the ECF using a nuFFT: A fast and objective probability density estimation method". Computational Statistics & Data Analysis. 79: 222–234. doi:10.1016/j.csda.2014.06.002.
- O’Brien, Travis A.; Kashinath, Karthik; Cavanaugh, Nicholas R.; Collins, William D.; O’Brien, John P. (2016). "A fast and objective multidimensional kernel density estimation method: fastKDE" (PDF). Computational Statistics & Data Analysis. 101: 148–160. doi:10.1016/j.csda.2016.02.014.
External links
- mvstat.net A collection of peer-reviewed articles of the mathematical details of multivariate kernel density estimation and their bandwidth selectors on an mvstat.net web page.
- kde2d.m A Matlab function for bivariate kernel density estimation.
- libagf A C++ library for multivariate, variable bandwidth kernel density estimation.
- akde.m A Matlab m-file for multivariate, variable bandwidth kernel density estimation.
- helit and pyqt_fit.kde Module in the PyQt-Fit package are Python libraries for multivariate kernel density estimation.