Mix network
Mix networks[1] are routing protocols that create hard-to-trace communications by using a chain of proxy servers known as mixes which take in messages from multiple senders, shuffle them, and send them back out in random order to the next destination (possibly another mix node). This breaks the link between the source of the request and the destination, making it harder for eavesdroppers to trace end-to-end communications. Furthermore, mixes only know the node that it immediately received the message from, and the immediate destination to send the shuffled messages to, making the network resistant to malicious mix nodes.[2][3]
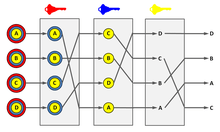
Each message is encrypted to each proxy using public key cryptography; the resulting encryption is layered like a Russian doll (except that each "doll" is of the same size) with the message as the innermost layer. Each proxy server strips off its own layer of encryption to reveal where to send the message next. If all but one of the proxy servers are compromised by the tracer, untraceability can still be achieved against some weaker adversaries.
The concept of mix networks was first described by David Chaum in 1981.[4] Applications that are based on this concept include anonymous remailers (such as Mixmaster), onion routing, garlic routing, and key-based routing (including Tor, I2P, and Freenet).
How it works

Participant A prepares a message for delivery to participant B by appending a random value R to the message, sealing it with the addressee's public key , appending B's address, and then sealing the result with the mix's public key . M opens it with his private key, now he knows B's address, and he sends to B.



Message format

To accomplish this, the sender takes the mix's public key (), and uses it to encrypt an envelope containing a random string (), a nested envelope addressed to the recipient, and the email address of the recipient (B). This nested envelope is encrypted with the recipient's public key (), and contains another random string (R0), along with the body of the message being sent. Upon receipt of the encrypted top-level envelope, the mix uses its secret key to open it. Inside, it finds the address of the recipient (B) and an encrypted message bound for B. The random string () is discarded.

is needed in the message in order to prevent an attacker from guessing messages. It is assumed that the attacker can observe all incoming and outgoing messages. If the random string is not used (i.e. only is sent to ) and an attacker has a good guess that the message was sent, he can test whether holds, whereby he can learn the content of the message. By appending the random string the attacker is prevented from performing this kind of attack; even if he should guess the correct message (i.e. is true) he won't learn if he is right since he doesn't know the secret value . Practically, functions as a salt.






Return addresses
What is needed now is a way for B to respond to A while still keeping the identity of A secret from B.
A solution is for A to form an untraceable return address where is its own real address, is a public one-time key chosen for the current occasion only, and is a key that will also act as a random string for purposes of sealing. Then, A can send this return address to B as part of a message sent by the techniques already described.




B sends to M, and M transforms it to .


This mix uses the string of bits that it finds after decrypting the address part as a key to re-encrypt the message part . Only the addressee, A, can decrypt the resulting output because A created both and . The additional key assures that the mix cannot see the content of the reply-message.


The following indicates how B uses this untraceable return address to form a response to A, via a new kind of mix:
The message from A B:


Reply message from BA:

Where: = B’s public key, = the mix's public key.
A destination can reply to a source without sacrificing source anonymity. The reply message shares all of the performance and security benefits with the anonymous messages from source to destination.
Vulnerabilities
Although mix networks provide security even if an adversary is able to view the entire path, mixing is not absolutely perfect. Adversaries can provide long term correlation attacks and track the sender and receiver of the packets.[5]
Threat model
An adversary can perform a passive attack by monitoring the traffic to and from the mix network. Analyzing the arrival times between multiple packets can reveal information. Since no changes are actively made to the packets, an attack like this is hard to detect. In a worst case of an attack, we assume that all the links of the network are observable by the adversary and the strategies and infrastructure of the mix network are known.
A packet on an input link cannot be correlated to a packet on the output link based on information about the time the packet was received, the size of the packet, or the content of the packet. Packet correlation based on packet timing is prevented by batching and correlation based on content and packet size is prevented by encryption and packet padding, respectively.
Inter-packet intervals, that is, the time difference between observation of two consecutive packets on two network links, is used to infer if the links carry the same connection. The encryption and padding does not affect the inter-packet interval related to the same IP flow. Sequences of inter-packet interval vary greatly between connections, for example in web browsing, the traffic occurs in bursts. This fact can be used to identify a connection.
Active attack
Active attacks can be performed by injecting bursts of packets that contain unique timing signatures into the targeted flow. The attacker can perform attacks to attempt to identify these packets on other network links. The attacker might not be able to create new packets due to the required knowledge of symmetric keys on all the subsequent mixes. Replay packets cannot be used either as they are easily preventable through hashing and caching.
Artificial gap
Large gaps can be created in the target flow, if the attacker drops large volumes of consecutive packets in the flow. For example, a simulation is run sending 3000 packets to the target flow, where the attacker drops the packets 1 second after the start of the flow. As the number of consecutive packets dropped increases, the effectiveness of defensive dropping decreases significantly. Introducing a large gap will almost always create a recognizable feature.
Artificial bursts
The attacker can create artificial bursts. This is done by creating a signature from artificial packets by holding them on a link for a certain period of time and then releasing them all at once. Defense dropping provides no defense in this scenario and the attacker can identify the target flow. There are other defense measures that can be taken to prevent this attack. One such solution can be adaptive padding algorithms. The more the packets are delayed, the easier it is to identify the behavior and thus better defense can be observed.
Other time analysis attacks
An attacker may also look into other timing attacks other than inter-packet intervals. The attacker can actively modify packet streams to observe the changes caused in the network's behavior. Packets can be corrupted to force re-transmission of TCP packets, which the behavior is easily observable to reveal information.[6]
Sleeper attack
Assuming an adversary can see messages being sent and received into threshold mixes but they can't see the internal working of these mixes or what is sent by the same. If the adversary has left their own messages in respective mixes and they receive one of the two, they are able to determine the message sent and the corresponding sender. The adversary has to place their messages (active component) in the mix at any given time and the messages must remain there prior to a message being sent. This is not typically an active attack. Weaker adversaries can use this attack in combination with other attacks to cause more issues.
Mix networks derive security by changing order of messages they receive to avoid creating significant relation between the incoming and outgoing messages. Mixes create interference between messages. The interference puts bounds on the rate of information leak to an observer of the mix. In a mix of size n, an adversary observing input to and output from the mix has an uncertainty of order n in determining a match. A sleeper attack can take advantage of this. In a layered network of threshold mixes with a sleeper in each mix, there is a layer receiving inputs from senders and a second layer of mixes that forward messages to the final destination. From this, the attacker can learn that the received message could not have come from the sender into any layer 1 mix that did not fire. There is a higher probability of matching the sent and received messages with these sleepers thus communication is not completely anonymous. Mixes may also be purely timed: they randomize the order of messages received in a particular interval and attach some of them with the mixes, forwarding them at the end of the interval despite what has been received in that interval. Messages that are available for mixing will interfere, but if no messages are available, there is no interference with received messages.[7]
History
David Chaum published the concept of Mix Networks in 1979 in his paper: "Untraceable electronic mail, return addresses, and digital pseudonyms". The paper was for his master's degree thesis work, shortly after he was first introduced to the field of cryptography through the work of public key cryptography, Martin Hellman, Whitfield Diffie and Ralph Merkle. While public key cryptography encrypted the security of information, Chaum believed there to be personal privacy vulnerabilities in the meta data found in communications. Some vulnerabilities that enabled the compromise of personal privacy included time of messages sent and received, size of messages and the address of the original sender. He cites Martin Hellman and Whitfield's paper "New Directions in Cryptography" (1976) in his work.
References
- Also known as "digital mixes"
- Claudio A. Ardagna; et al. (2009). "Privacy Preservation over Untrusted Mobile Networks". In Bettini, Claudio; et al. (eds.). Privacy In Location-Based Applications: Research Issues and Emerging Trends. Springer. p. 88. ISBN 9783642035111.
- Danezis, George (2003-12-03). "Mix-Networks with Restricted Routes". In Dingledine, Roger (ed.). Privacy Enhancing Technologies: Third International Workshop, PET 2003, Dresden, Germany, March 26–28, 2003, Revised Papers. Vol. 3. Springer. ISBN 9783540206101.
- David Chaum, Untraceable electronic mail, return addresses, and digital pseudonyms, Comm. ACM, 24, 2 (Feb. 1981); 84–90
- Tom Ritter, "the differences between onion routing and mix networks", ritter.vg Retrieved December 8, 2016.
- Shmatikov, Vitaly; Wang, Ming-Hsiu (2006). Timing Analysis in Low-Latency Mix Networks: Attacks and Defenses. European Symposium on Research in Computer Security. Lecture Notes in Computer Science. 4189. pp. 18–33. CiteSeerX 10.1.1.64.8818. doi:10.1007/11863908_2. ISBN 978-3-540-44601-9.
- Paul Syverson, "Sleeping dogs lie on a bed of onions but wake when mixed", Privacy Enhancing Technologies Symposium Retrieved December 8, 2016.