Mark-compact algorithm
In computer science, a mark-compact algorithm is a type of garbage collection algorithm used to reclaim unreachable memory. Mark-compact algorithms can be regarded as a combination of the mark-sweep algorithm and Cheney's copying algorithm. First, reachable objects are marked, then a compacting step relocates the reachable (marked) objects towards the beginning of the heap area. Compacting garbage collection is used by Microsoft's Common Language Runtime and by the Glasgow Haskell Compiler.
Algorithms
After marking the live objects in the heap in the same fashion as the mark-sweep algorithm, the heap will often be fragmented. The goal of mark-compact algorithms is to shift the live objects in memory together so the fragmentation is eliminated. The challenge is to correctly update all pointers to the moved objects, most of which will have new memory addresses after the compaction. The issue of handling pointer updates is handled in different ways.
Table-based compaction
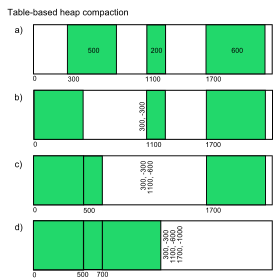
A table-based algorithm was first described by Haddon and Waite in 1967.[1] It preserves the relative placement of the live objects in the heap, and requires only a constant amount of overhead.
Compaction proceeds from the bottom of the heap (low addresses) to the top (high addresses). As live (that is, marked) objects are encountered, they are moved to the first available low address, and a record is appended to a break table of relocation information. For each live object, a record in the break table consists of the object's original address before the compaction and the difference between the original address and the new address after compaction. The break table is stored in the heap that is being compacted, but in an area that are marked as unused. To ensure that compaction will always succeed, the minimum object size in the heap must be larger than or the same size as a break table record.
As compaction progresses, relocated objects are copied towards the bottom of the heap. Eventually an object will need to be copied to the space occupied by the break table, which now must be relocated elsewhere. These movements of the break table, (called rolling the table by the authors) cause the relocation records to become disordered, requiring the break table to be sorted after the compaction is complete. The cost of sorting the break table is O(n log n), where n is the number of live objects that were found in the mark stage of the algorithm.
Finally, the break table relocation records are used to adjust pointer fields inside the relocated objects. The live objects are examined for pointers, which can be looked up in the sorted break table of size n in O(log n) time if the break table is sorted, for a total running time of O(n log n). Pointers are then adjusted by the amount specified in the relocation table.
LISP2 algorithm
In order to avoid O(n log n) complexity, the LISP2 algorithm uses 3 different passes over the heap. In addition, heap objects must have a separate forwarding pointer slot that is not used outside of garbage collection.
After standard marking, the algorithm proceeds in the following 3 passes:
- Compute the forwarding location for live objects.
- Keep track of a free and live pointer and initialize both to the start of heap.
- If the live pointer points to a live object, update that object's forwarding pointer to the current free pointer and increment the free pointer according to the object's size.
- Move the live pointer to the next object
- End when the live pointer reaches the end of heap.
- Update all pointers
- For each live object, update its pointers according to the forwarding pointers of the objects they point to.
- Move objects
- For each live object, move its data to its forwarding location.
This algorithm is O(n) on the size of the heap; it has a better complexity than the table-based approach, but the table-based approach's n is the size of the used space only, not the entire heap space as in the LISP2 algorithm. However, the LISP2 algorithm is simpler to implement.
See also
- Dead-code elimination
References
- B. K. Haddon and W. M. Waite (August 1967). "A compaction procedure for variable-length storage elements" (PDF). Computer Journal. 10 (2): 162–165. doi:10.1093/comjnl/10.2.162.CS1 maint: uses authors parameter (link)