Interleaved memory
In computing, interleaved memory is a design which compensates for the relatively slow speed of dynamic random-access memory (DRAM) or core memory, by spreading memory addresses evenly across memory banks. That way, contiguous memory reads and writes use each memory bank in turn, resulting in higher memory throughput due to reduced waiting for memory banks to become ready for the operations.
It is different from multi-channel memory architectures, primarily as interleaved memory does not add more channels between the main memory and the memory controller. However, channel interleaving is also possible, for example in freescale i.MX6 processors, which allow interleaving to be done between two channels.
Overview
With interleaved memory, memory addresses are allocated to each memory bank in turn. For example, in an interleaved system with two memory banks (assuming word-addressable memory), if logical address 32 belongs to bank 0, then logical address 33 would belong to bank 1, logical address 34 would belong to bank 0, and so on. An interleaved memory is said to be n-way interleaved when there are n banks and memory location i resides in bank i mod n.
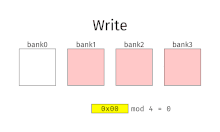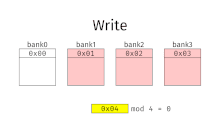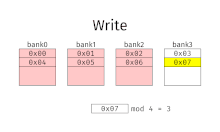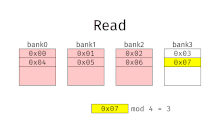
Interleaved memory results in contiguous reads (which are common both in multimedia and execution of programs) and contiguous writes (which are used frequently when filling storage or communication buffers) actually using each memory bank in turn, instead of using the same one repeatedly. This results in significantly higher memory throughput as each bank has a minimum waiting time between reads and writes.
Interleaved DRAM
Main memory (random-access memory, RAM) is usually composed of a collection of DRAM memory chips, where a number of chips can be grouped together to form a memory bank. It is then possible, with a memory controller that supports interleaving, to lay out these memory banks so that the memory banks will be interleaved.
Data in DRAM is stored in units of pages. Each DRAM bank has a row buffer that serves as a cache for accessing any page in the bank. Before a page in the DRAM bank is read, it is first loaded into the row-buffer. If the page is immediately read from the row-buffer (or a row-buffer hit), it has the shortest memory access latency in one memory cycle. If it is a row buffer miss, which is also called a row-buffer conflict, it is slower because the new page has to be loaded into the row-buffer before it is read. Row-buffer misses happen as access requests on different memory pages in the same bank are serviced. A row-buffer conflict incurs a substantial delay for a memory access. In contrast, memory accesses to different banks can proceed in parallel with a high throughput.
In traditional (flat) layouts, memory banks can be allocated a contiguous block of memory addresses, which is very simple for the memory controller and gives equal performance in completely random access scenarios, when compared to performance levels achieved through interleaving. However, in reality memory reads are rarely random due to locality of reference, and optimizing for close together access gives far better performance in interleaved layouts.
The way memory is addressed has no effect on the access time for memory locations which are already cached, having an impact only on memory locations which need to be retrieved from DRAM.
History
Early research into interleaved memory was performed at IBM in the 60s and 70s in relation to the IBM 7030 Stretch computer,[1] but development went on for decades improving design, flexibility and performance to produce modern implementations.
See also
- Multi-channel memory architecture
- DIMM (dual in-line memory module)
References
- Mark Smotherman (July 2010). "IBM Stretch (7030) — Aggressive Uniprocessor Parallelism". clemson.edu. Retrieved 2013-12-07.