Influential observation
In statistics, an influential observation is an observation for a statistical calculation whose deletion from the dataset would noticeably change the result of the calculation.[1] In particular, in regression analysis an influential point is one whose deletion has a large effect on the parameter estimates.[2]
Assessment
Various methods have been proposed for measuring influence.[3][4] Assume an estimated regression , where is an n×1 column vector for the response variable, is the n×k design matrix of explanatory variables (including a constant), is the n×1 residual vector, and is a k×1 vector of estimates of some population parameter . Also define , the projection matrix of . Then we have the following measures of influence:







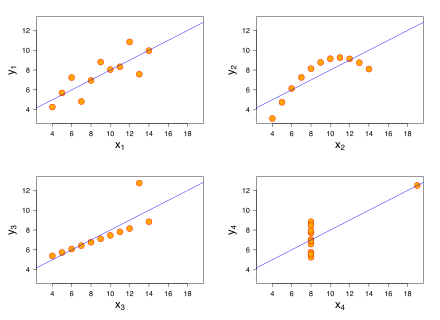
- , where denotes the coefficients estimated with the i-th row of deleted, denotes the i-th row of . Thus DFBETA measures the difference in each parameter estimate with and without the influential point. There is a DFBETA for each point and each observation (if there are N points and k variables there are N·k DFBETAs).[5] Table shows DFBETAs for the third dataset from Anscombe's quartet (bottom left chart in the figure):





| x | y | intercept | slope |
| 10.0 | 7.46 | -0.005 | -0.044 |
| 8.0 | 6.77 | -0.037 | 0.019 |
| 13.0 | 12.74 | -357.910 | 525.268 |
| 9.0 | 7.11 | -0.033 | 0 |
| 11.0 | 7.81 | 0.049 | -0.117 |
| 14.0 | 8.84 | 0.490 | -0.667 |
| 6.0 | 6.08 | 0.027 | -0.021 |
| 4.0 | 5.39 | 0.241 | -0.209 |
| 12.0 | 8.15 | 0.137 | -0.231 |
| 7.0 | 6.42 | -0.020 | 0.013 |
| 5.0 | 5.73 | 0.105 | -0.087 |
Outliers, leverage and influence
An outlier may be defined as a data point that differs significantly from other observations.[6][7] A high-leverage point are observations made at extreme values of the independent variables.[8] Both types of atypical observations will force the regression line to be close to the point.[2] In Anscombe's quartet, the bottom right image has a point with high leverage and the bottom left image has an outlying point.
See also
References
- Burt, James E.; Barber, Gerald M.; Rigby, David L. (2009), Elementary Statistics for Geographers, Guilford Press, p. 513, ISBN 9781572304840.
- Everitt, Brian (1998). The Cambridge Dictionary of Statistics. Cambridge, UK New York: Cambridge University Press. ISBN 0-521-59346-8.
- Winner, Larry (March 25, 2002). "Influence Statistics, Outliers, and Collinearity Diagnostics".
- Belsley, David A.; Kuh, Edwin; Welsh, Roy E. (1980). Regression Diagnostics: Identifying Influential Data and Sources of Collinearity. Wiley Series in Probability and Mathematical Statistics. New York: John Wiley & Sons. pp. 11–16. ISBN 0-471-05856-4.
- "Outliers and DFBETA" (PDF). Archived (PDF) from the original on May 11, 2013.
- Grubbs, F. E. (February 1969). "Procedures for detecting outlying observations in samples". Technometrics. 11 (1): 1–21. doi:10.1080/00401706.1969.10490657.
An outlying observation, or "outlier," is one that appears to deviate markedly from other members of the sample in which it occurs.
- Maddala, G. S. (1992). "Outliers". Introduction to Econometrics (2nd ed.). New York: MacMillan. pp. 89. ISBN 978-0-02-374545-4.
An outlier is an observation that is far removed from the rest of the observations.
- Everitt, B. S. (2002). Cambridge Dictionary of Statistics. Cambridge University Press. ISBN 0-521-81099-X.
Further reading
- Dehon, Catherine; Gassner, Marjorie; Verardi, Vincenzo (2009). "Beware of 'Good' Outliers and Overoptimistic Conclusions". Oxford Bulletin of Economics and Statistics. 71 (3): 437–452. doi:10.1111/j.1468-0084.2009.00543.x.
- Kennedy, Peter (2003). "Robust Estimation". A Guide to Econometrics (Fifth ed.). Cambridge: The MIT Press. pp. 372–388. ISBN 0-262-61183-X.