GenBank
The GenBank sequence database is an open access, annotated collection of all publicly available nucleotide sequences and their protein translations. It is produced and maintained by the National Center for Biotechnology Information (NCBI; a part of the National Institutes of Health in the United States) as part of the International Nucleotide Sequence Database Collaboration (INSDC).
| Content | |
|---|---|
| Description | Nucleotide sequences for more than 300,000 organisms with supporting bibliographic and biological annotation. |
| Data types captured |
|
| Organisms | All |
| Contact | |
| Research center | NCBI |
| Primary citation | PMID 21071399 |
| Release date | 1982 |
| Access | |
| Data format | |
| Website | NCBI |
| Download URL | ncbi ftp |
| Web service URL | |
| Tools | |
| Web | BLAST |
| Standalone | BLAST |
| Miscellaneous | |
| License | Unclear[1] |
GenBank and its collaborators receive sequences produced in laboratories throughout the world from more than 100,000 distinct organisms. The database started in 1982 by Walter Goad and Los Alamos National Laboratory. GenBank has become an important database for research in biological fields and has grown in recent years at an exponential rate by doubling roughly every 18 months.[2][3]
Release 194, produced in February 2013, contained over 150 billion nucleotide bases in more than 162 million sequences.[4] GenBank is built by direct submissions from individual laboratories, as well as from bulk submissions from large-scale sequencing centers.
Submissions
Only original sequences can be submitted to GenBank. Direct submissions are made to GenBank using BankIt, which is a Web-based form, or the stand-alone submission program, Sequin. Upon receipt of a sequence submission, the GenBank staff examines the originality of the data and assigns an accession number to the sequence and performs quality assurance checks. The submissions are then released to the public database, where the entries are retrievable by Entrez or downloadable by FTP. Bulk submissions of Expressed Sequence Tag (EST), Sequence-tagged site (STS), Genome Survey Sequence (GSS), and High-Throughput Genome Sequence (HTGS) data are most often submitted by large-scale sequencing centers. The GenBank direct submissions group also processes complete microbial genome sequences.
History
Walter Goad of the Theoretical Biology and Biophysics Group at Los Alamos National Laboratory and others established the Los Alamos Sequence Database in 1979, which culminated in 1982 with the creation of the public GenBank.[5] Funding was provided by the National Institutes of Health, the National Science Foundation, the Department of Energy, and the Department of Defense. LANL collaborated on GenBank with the firm Bolt, Beranek, and Newman, and by the end of 1983 more than 2,000 sequences were stored in it.
In the mid 1980s, the Intelligenetics bioinformatics company at Stanford University managed the GenBank project in collaboration with LANL.[6] As one of the earliest bioinformatics community projects on the Internet, the GenBank project started BIOSCI/Bionet news groups for promoting open access communications among bioscientists. During 1989 to 1992, the GenBank project transitioned to the newly created National Center for Biotechnology Information.[7]


Growth
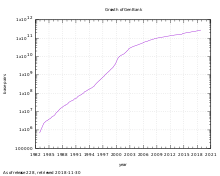
The GenBank release notes for release 162.0 (October 2007) state that "from 1982 to the present, the number of bases in GenBank has doubled approximately every 18 months".[4][8] As of 15 June 2019, GenBank release 232.0 has 213,383,758 loci, 329,835,282,370 bases, from 213,383,758 reported sequences.[4]
The GenBank database includes additional data sets that are constructed mechanically from the main sequence data collection, and therefore are excluded from this count.
| Organism | base pairs |
|---|---|
| Homo sapiens | 1.6310774187×1010 |
| Mus musculus | 9.974977889×109 |
| Rattus norvegicus | 6.521253272×109 |
| Bos taurus | 5.386258455×109 |
| Zea mays | 5.062731057×109 |
| Sus scrofa | 4.88786186×109 |
| Danio rerio | 3.120857462×109 |
| Strongylocentrotus purpuratus | 1.435236534×109 |
| Macaca mulatta | 1.256203101×109 |
| Oryza sativa Japonica Group | 1.255686573×109 |
| Nicotiana tabacum | 1.197357811×109 |
| Xenopus (Silurana) tropicalis | 1.249938611×109 |
| Drosophila melanogaster | 1.11996522×109 |
| Pan troglodytes | 1.008323292×109 |
| Arabidopsis thaliana | 1.144226616×109 |
| Canis lupus familiaris | 951,238,343 |
| Vitis vinifera | 999,010,073 |
| Gallus gallus | 899,631,338 |
| Glycine max | 906,638,854 |
| Triticum aestivum | 898,689,329 |
Incomplete identifications
Public databases which may be searched using the National Center for Biotechnology Information Basic Local Alignment Search Tool (NCBI BLAST), lack peer-reviewed sequences of type strains and sequences of non-type strains. On the other hand, while commercial databases potentially contain high-quality filtered sequence data, there are a limited number of reference sequences.
A paper released in the Journal of Clinical Microbiology[10] evaluated the 16S rRNA gene sequencing results analyzed with GenBank in conjunction with other freely available, quality-controlled, web-based public databases, such as the EzTaxon-e (https://web.archive.org/web/20130928154318/http://eztaxon-e.ezbiocloud.net/) and the BIBI (https://web.archive.org/web/20151001000357/http://pbil.univ-lyon1.fr/bibi/) databases. The results showed that analyses performed using GenBank combined with EzTaxon-e (kappa = 0.79) were more discriminative than using GenBank (kappa = 0.66) or other databases alone.
See also
- Ensembl
- Human Protein Reference Database (HPRD)
- Sequence analysis
- UniProt
- List of sequenced eukaryotic genomes
- List of sequenced archaeal genomes
- RefSeq — the Reference Sequence Database
- Geneious — includes a GenBank Submission Tool
- Open science data
References
- The download page at UCSC says "NCBI places no restrictions on the use or distribution of the GenBank data. However, some submitters may claim patent, copyright, or other intellectual property rights in all or a portion of the data they have submitted. NCBI is not in a position to assess the validity of such claims, and therefore cannot provide comment or unrestricted permission concerning the use, copying, or distribution of the information contained in GenBank."
- Benson D; Karsch-Mizrachi, I.; Lipman, D. J.; Ostell, J.; Wheeler, D. L.; et al. (2008). "GenBank". Nucleic Acids Research. 36 (Database): D25–D30. doi:10.1093/nar/gkm929. PMC 2238942. PMID 18073190.
- Benson D; Karsch-Mizrachi, I.; Lipman, D. J.; Ostell, J.; Sayers, E. W.; et al. (2009). "GenBank". Nucleic Acids Research. 37 (Database): D26–D31. doi:10.1093/nar/gkn723. PMC 2686462. PMID 18940867.
- "GenBank release notes". NCBI.
- Hanson, Todd (2000-11-21). "Walter Goad, GenBank founder, dies". Newsbulletin: obituary. Los Alamos National Laboratory.
- LANL GenBank History
- Benton D (1990). "Recent changes in the GenBank On-line Service". Nucleic Acids Research. 18 (6): 1517–1520. doi:10.1093/nar/18.6.1517. PMC 330520. PMID 2326192.
- Benson, D. A.; Cavanaugh, M.; Clark, K.; Karsch-Mizrachi, I.; Lipman, D. J.; Ostell, J.; Sayers, E. W. (2012). "GenBank". Nucleic Acids Research. 41 (Database issue): D36–D42. doi:10.1093/nar/gks1195. PMC 3531190. PMID 23193287.
- Benson DA, Karsch-Mizrachi I, Lipman DJ, Ostell J, Sayers EW (January 2011). "GenBank". Nucleic Acids Res. 39 (Database issue): D32–37. doi:10.1093/nar/gkq1079. PMC 3013681. PMID 21071399.
- Kyung Sun Parka, Chang-Seok Kia, Cheol-In Kangb, Yae-Jean Kimc, Doo Ryeon Chungb, Kyong Ran Peckb, Jae-Hoon Songb and Nam Yong Lee (May 2012). "Evaluation of the GenBank, EzTaxon, and BIBI Services for Molecular Identification of Clinical Blood Culture Isolates That Were Unidentifiable or Misidentified by Conventional Methods". J. Clin. Microbiol. 50 (5): 1792–1795. doi:10.1128/JCM.00081-12. PMC 3347139. PMID 22403421.CS1 maint: uses authors parameter (link)

External links
- GenBank
- Example sequence record, for hemoglobin beta
- BankIt
- Sequin — a stand-alone software tool developed by the NCBI for submitting and updating entries to the GenBank sequence database.
- EMBOSS — free, open source software for molecular biology
- GenBank, RefSeq, TPA and UniProt: What's in a Name?
| Authority control |
|
|---|