Federated learning
Federated learning (also known as collaborative learning) is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging them. This approach stands in contrast to traditional centralized machine learning techniques where all the local datasets are uploaded to one server, as well as to more classical decentralized approaches which assume that local data samples are identically distributed.
Federated learning enables multiple actors to build a common, robust machine learning model without sharing data, thus allowing to address critical issues such as data privacy, data security, data access rights and access to heterogeneous data. Its applications are spread over a number of industries including defense, telecommunications, IoT, and pharmaceutics.
Definition
Federated learning aims at training a machine learning algorithm, for instance deep neural networks, on multiple local datasets contained in local nodes without explicitly exchanging data samples. The general principle consists in training local models on local data samples and exchanging parameters (e.g. the weights and biases of a deep neural network) between these local nodes at some frequency to generate a global model shared by all nodes.
The main difference between federated learning and distributed learning lies in the assumptions made on the properties of the local datasets,[1] as distributed learning originally aims at parallelizing computing power where federated learning originally aims at training on heterogeneous datasets. While distributed learning also aims at training a single model on multiple servers, a common underlying assumption is that the local datasets are identically distributed (i.i.d.) and roughly have the same size. None of these hypotheses are made for federated learning; instead, the datasets are typically heterogeneous and their sizes may span several orders of magnitude. Moreover, the clients involved in federated learning may be unreliable as they are subject to more failures or drop out since they commonly rely on less powerful communication media (i.e. Wi-fi) and battery-powered systems (i.e. smartphones and IoT devices) compared to distributed learning where nodes are typically datacenters that have powerful computational capabilities and are connected one another with fast networks.[2]
Centralized federated learning
In the centralized federated learning setting, a central server is used to orchestrate the different steps of the algorithms and coordinate all the participating nodes during the learning process. The server is responsible for the nodes selection at the beginning of the training process and for the aggregation of the received model updates. Since all the selected nodes have to send updates to a single entity, the server may become a bottleneck of the system.[2]
Decentralized federated learning
In the decentralized federated learning setting, the nodes are able to coordinate themselves to obtain the global model. This setup prevents single point failures as the model updates are exchanged only between interconnected nodes without the orchestration of the central server. Nevertheless, the specific network topology may affect the performances of the learning process.[2] See blockchain-based federated learning[3] and the references therein.
Main features
Iterative learning
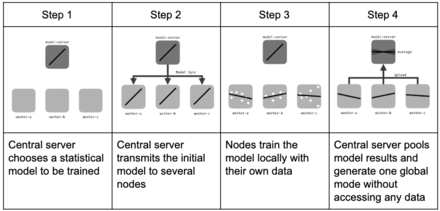
To ensure good task performance of a final, central machine learning model, federated learning relies on an iterative process broken up into an atomic set of client-server interactions known as a federated learning round. Each round of this process consists in transmitting the current global model state to participating nodes, training local models on these local nodes to produce a set of potential model updates at each node, and then aggregating and processing these local updates into a single global update and applying it to the global model.[2]
In the methodology below, a central server is used for aggregation, while local nodes perform local training depending on the central server's orders. However, other strategies lead to the same results without central servers, in a peer-to-peer approach, using gossip[4] or consensus methodologies.[5]
Assuming a federated round composed by one iteration of the learning process, the learning procedure can be summarized as follows:[6]
- Initialization: according to the server inputs, a machine learning model (e.g., linear regression, neural network, boosting) is chosen to be trained on local nodes and initialized. Then, nodes are activated and wait for the central server to give the calculation tasks.
- Client selection: a fraction of local nodes is selected to start training on local data. The selected nodes acquire the current statistical model while the others wait for the next federated round.
- Configuration: the central server orders selected nodes to undergo training of the model on their local data in a pre-specified fashion (e.g., for some mini-batch updates of gradient descent).
- Reporting: each selected node sends its local model to the server for aggregation. The central server aggregates the received models and sends back the model updates to the nodes. It also handles failures for disconnected nodes or lost model updates. The next federated round is started returning to the client selection phase.
- Termination: once a pre-defined termination criterion is met (e.g., a maximum number of iterations is reached or the model accuracy is grater than a threshold) the central server aggregates the updates and finalizes the global model.
The procedure considered before assumes synchronized model updates. Recent federated learning developments introduced novel techniques to tackle asynchronicity during the training process. Compared to synchronous approaches where local models are exchanged once the computations have been performed for all layers of the neural network, asynchronous ones leverage the properties of neural networks to exchange model updates as soon as the computations of a certain layer are available. These techniques are also commonly referred to as split learning[7][8] and they can be applied both at training and inference time regardless of centralized or decentralized federated learning settings.[2]
Non-iid data
In most cases, the assumption of independent and identically distributed samples across local nodes does not hold for federated learning setups. Under this setting, the performances of the training process may vary significantly according to the unbalancedness of local data samples as well as the particular probability distribution of the training examples (i.e., features and labels) stored at the local nodes. To further investigate the effects of non-iid data, the following description considers the main categories presented in the by Peter Kiarouz and al. in 2019.[2]
The description of non-iid data relies on the analysis of the joint probability between features and labels for each node. This allows to decouple each contribution according to the specific distribution available at the local nodes. The main categories for non-iid data can be summarized as follows:[2]
- Covariate shift: local nodes may store examples that have different statistical distributions compared to other nodes. An example occurs in natural language processing datasets where people typically write the same digits/letters with different stroke widths or slants.[2]
- Prior probability shift: local nodes may store labels that have different statistical distributions compared to other nodes. This can happen if datasets are regional and/or demographically partitioned. For example, datasets containing images of animals vary significantly from country to country.[2]
- Concept shift (same label, different features): local nodes may share the same labels but some of them correspond to different features at different local nodes. For example, images that depict a particular object can vary according to the weather condition in which they were captured.[2]
- Concept shift (same features, different labels): local nodes may share the same features but some of them correspond to different labels at different local nodes. For example, in natural language processing, the sentiment analysis may yield different sentiments even if the same text is observed.[2]
- Unbalancedness: the data available at the local nodes may vary significantly in size.[2]
Other non-iid data descriptors take into account the dynamic variation of the network topology,[9] due to failures or ineligibility of local nodes during the federated learning process, or dataset shifts, where the nodes participating in the training phase for learning the global model may not be eligible during inference due to insufficient computational capabilities. This results in a difference between the statistics of training and testing data samples.[2]
Algorithmic hyper-parameters
Network topology
The way the statistical local outputs are pooled and the way the nodes communicate with each other can change from the centralized model explained in the previous section. This leads to a variety of federated learning approaches: for instance no central orchestrating server, or stochastic communication.[10]
In particular, orchestrator-less distributed networks are one important variation. In this case, there is no central server dispatching queries to local nodes and aggregating local models. Each local node sends its outputs to a several randomly-selected others, which aggregate their results locally. This restrains the number of transactions, thereby sometimes reducing training time and computing cost.[11]
Federated learning parameters
Once the topology of the node network is chosen, one can control different parameters of the federated learning process (in opposition to the machine learning model's own hyperparameters) to optimize learning:
- Number of federated learning rounds:
- Total number of nodes used in the process:
- Fraction of nodes used at each iteration for each node:
- Local batch size used at each learning iteration:




Other model-dependent parameters can also be tinkered with, such as:
- Number of iterations for local training before pooling:
- Local learning rate:


Those parameters have to be optimized depending on the constraints of the machine learning application (e.g., available computing power, available memory, bandwidth). For instance, stochastically choosing a limited fraction of nodes for each iteration diminishes computing cost and may prevent overfitting, in the same way that stochastic gradient descent can reduce overfitting.
Federated learning variations
In this section, the exposition of the paper published by H. Brendan McMahan and al. in 2017 is followed.[12]
To describe the federated strategies, let us introduce some notations:
- : total number of clients;
- : index of clients;
- : number of data samples available during training for client ;
- : model's weight vector on client , at the federated round ;
- : loss function for weights and batch ;
- : number of local epochs;








Federated Stochastic Gradient Descent (FedSGD)
Deep learning training mainly relies on variants of stochastic gradient descent, where gradients are computed on a random subset of the total dataset and then used to make one step of the gradient descent.
Federated stochastic gradient descent[13] is the direct transposition of this algorithm to the federated setting, but by using a random fraction of the nodes and using all the data on this node. The gradients are averaged by the server proportionally to the number of training samples on each node, and used to make a gradient descent step.
Federated averaging
Federated averaging (FedAvg) is a generalization of FedSGD, which allows local nodes to perform more than one batch update on local data and exchanges the updated weights rather than the gradients. The rationale behind this generalization is that in FedSGD, if all local nodes start from the same initialization, averaging the gradients is strictly equivalent to averaging the weights themselves. Further, averaging tuned weights coming from the same initialization does not necessarily hurt the resulting averaged model's performance.[12]
Technical limitations
Federated learning requires frequent communication between nodes during the learning process. Thus, it requires not only enough local computing power and memory, but also high bandwidth connections to be able to exchange parameters of the machine learning model. However, the technology also avoid data communication, which can require significant resources before starting centralized machine learning. Nevertheless, the devices typically employed in federated learning are communication-constrained, for example IoT devices or smartphones are generally connected to Wi-fi networks, thus, even if the models are commonly less expensive to be transmitted compared to raw data, federated learning mechanisms may not be suitable in their general form.[2]
Federated learning raises several statistical challenges:
- Heterogeneity between the different local datasets: each node may have some bias with respect to the general population, and the size of the datasets may vary significantly;
- Temporal heterogeneity: each local dataset's distribution may vary with time;
- Interoperability of each node's dataset is a prerequisite;
- Each node's dataset may require regular curations;
- Hiding training data might allow attackers to inject backdoors into the global model;[14]
- Lack of access to global training data makes it harder to identify unwanted biases entering the training e.g. age, gender, sexual orientation;
- Partial or total loss of model updates due to node failures affecting the global model.[2]
Properties of federated learning
Privacy by design
The main advantage of using federated approaches to machine learning is to ensure data privacy or data secrecy. Indeed, no local data is uploaded externally, concatenated or exchanged. Since the entire database is segmented into local bits, this makes it more difficult to hack into it.
With federated learning, only machine learning parameters are exchanged. In addition, such parameters can be encrypted before sharing between learning rounds to extend privacy and homomorphic encryption schemes can be used to directly make computations on the encrypted data without decrypting them beforehand. Despite such protective measures, these parameters may still leak information about the underlying data samples, for instance, by making multiple specific queries on specific datasets. Querying capability of nodes thus is a major attention point, which can be addressed using differential privacy or secure aggregation.[15]
Personalization
The generated model delivers insights based on the global patterns of nodes. However, if a participating node wishes to learn from global patterns but also adapt outcomes to its peculiar status, the federated learning methodology can be adapted to generate two models at once in a multi-task learning framework. In addition, clustering techniques may be applied to aggregate nodes that share some similarities after the learning process is completed. This allows the generalization of the models learned by the nodes according also to their local data.[16]
In the case of deep neural networks, it is possible to share some layers across the different nodes and keep some of them on each local node. Typically, first layers performing general pattern recognition are shared and trained all datasets. The last layers will remain on each local node and only be trained on the local node's dataset.[17]
Legal upsides of federated learning
Western legal frameworks emphasize more and more on data protection and data traceability. White House 2012 Report[18] recommended the application of a data minimization principle, which is mentioned in European GDPR.[19] In some cases, it is illegal to transfer data from a country to another (e.g., genomic data), however international consortia are sometimes necessary for scientific advances. In such cases federated learning brings solutions to train a global model while respecting security constraints.
Current research topics
Federated learning has started to emerge as an important research topic in 2015[1] and 2016,[20] with the first publications on federated averaging in telecommunication settings. Another important aspect of active research is the reduction of the communication burden during the federated learning process. In 2017 and 2018, publications have emphasized the development of resource allocation strategies, especially to reduce communication[12] requirements[21] between nodes with gossip algorithms[22] as well as on the characterization of the robusteness to differential privacy attacks.[23] Other research activities focus on the reduction of the bandwidth during training through sparsification and quantization methods,[24] where the machine learning models are sparsified and/or compressed before they are shared with other nodes. Recent research advancements are starting to consider real-word propagating channels[25] as in previous implementations ideal channels were assumed.
Use cases
Federated learning typically applies when individual actors need to train models on larger datasets than their own, but cannot afford to share the data in itself with other (e.g., for legal, strategic or economic reasons). The technology yet requires good connections between local servers and minimum computational power for each node.[2]
Google Gboard
One of the first use cases of federated learning was implemented by Google[6][26] for predictive keyboards. Under high regulatory pressure, it showed impossible to upload every user's text message to train the predictive algorithm for word guessing. Besides, such a process would hijack too much of the user's data. Despite the sometimes limited memory and computing power of smartphones, Google has made a compelling use case out of its G-board, as presented during the Google I/O 2019 event.[27]
Healthcare: Federated datasets from hospitals
In pharmaceutical research, real world data is used to create drug leads and synthetic control arms. Generating knowledge on complex biological problems requires to gather a lot of data from diverse medical institutions, which are eager to maintain control of their sensitive patient data. Federated learning enables researchers to train predictive models on many sensitive data in a transparent way without uploading them. To that end, the New-York based startup Owkin uses federated learning to connect researchers and to train ML models on distributed data at scale across multiple medical institutions without centralizing the data.[28][29][30]
Transportation: Self-driving cars
Self-driving car encapsulate many machine learning technologies to function: computer vision for analyzing obstacles, machine learning for adapting their pace to the environment (e.g., bumpiness of the road). Due to the potential high number of self-driving cars and the need for them to quickly respond to real world situations, traditional cloud approach may generate safety risks. Federated learning can represent a solution for limiting volume of data transfer and accelerating learning processes.[31][32]
Industry 4.0: smart manufacturing
In Industry 4.0, there is a widespread adoption of machine learning techniques[33] to improve the efficiency and effectiveness of industrial process while guaranteeing a high level of safety. Nevertheless, privacy of sensible data for industries and manufacturing companies is of paramount importance. Federated learning algorithms can be applied to these problems as they do not disclose any sensible data.[20]
References
- Federated Optimization: Distributed Optimization Beyond the Datacenter, Jakub Konecny, H. Brendan McMahan, Daniel Ramage, 2015
- Kairouz, Peter; and, al. (10 December 2019). "Advances and Open Problems in Federated Learning". arXiv:1912.04977 [cs, stat].
- "Federated Learning with Blockchain for Autonomous Vehicles: Analysis and Design Challenges". IEEE Transactions on Communications, 2020. doi:10.1109/TCOMM.2020.2990686.
- Decentralized Collaborative Learning of Personalized Models over Networks Paul Vanhaesebrouck, Aurélien Bellet, Marc Tommasi, 2017
- Savazzi, Stefano; Nicoli, Monica; Rampa, Vittorio (May 2020). "Federated Learning With Cooperating Devices: A Consensus Approach for Massive IoT Networks". IEEE Internet of Things Journal. 7 (5): 4641–4654. doi:10.1109/JIOT.2020.2964162.
- Towards federated learning at scale: system design, Keith Bonawitz Hubert Eichner and al., 2019
- Gupta, Otkrist; Raskar, Ramesh (14 October 2018). "Distributed learning of deep neural network over multiple agents". arXiv:1810.06060 [cs, stat].
- Vepakomma, Praneeth; Gupta, Otkrist; Swedish, Tristan; Raskar, Ramesh (3 December 2018). "Split learning for health: Distributed deep learning without sharing raw patient data". arXiv:1812.00564 [cs, stat].
- Eichner, Hubert; Koren, Tomer; McMahan, H. Brendan; Srebro, Nathan; Talwar, Kunal (22 April 2019). "Semi-Cyclic Stochastic Gradient Descent". arXiv:1904.10120 [cs, stat].
- Collaborative Deep Learning in Fixed Topology Networks, Zhanhong Jiang, Aditya Balu, Chinmay Hegde, Soumik Sarkar, 2017
- GossipGraD: Scalable Deep Learning using Gossip Communication based Asynchronous Gradient Descent, Jeff Daily, Abhinav Vishnu, Charles Siegel, Thomas Warfel, Vinay Amatya, 2018
- Communication-Efficient Learning of Deep Networks from Decentralized Data, H. Brendan McMahan and al. 2017
- Privacy Preserving Deep Learning, R. Shokri and V. Shmatikov, 2015
- How To Backdoor Federated Learning, Eugene Bagdasaryan, 2018
- Practical Secure Aggregation for Privacy Preserving Machine Learning, Keith Bonawitz, 2018
- Sattler, Felix; Müller, Klaus-Robert; Samek, Wojciech (4 October 2019). "Clustered Federated Learning: Model-Agnostic Distributed Multi-Task Optimization under Privacy Constraints". arXiv:1910.01991 [cs, stat].
- Arivazhagan, Manoj Ghuhan; Aggarwal, Vinay; Singh, Aaditya Kumar; Choudhary, Sunav (2 December 2019). "Federated Learning with Personalization Layers". arXiv:1912.00818 [cs, stat].
- "Consumer Data Privacy in a Networked World: A Framework for Protecting Privacy and Promoting Innovation in the Global Digital Economy". Journal of Privacy and Confidentiality. 4 (2). 1 March 2013. doi:10.29012/jpc.v4i2.623. ISSN 2575-8527.
- Recital 39 of the Regulation (EU) 2016/679 (General Data Protection Regulation)
- Federated Optimization: Distributed Machine Learning for On-Device Intelligence, Jakub Konečný, H. Brendan McMahan, Daniel Ramage and Peter Richtárik, 2016
- Federated Learning: Strategies for Improving Communication Efficiency, Jakub Konečný, H. Brendan McMahan, Felix X. Yu, Peter Richtárik, Ananda Theertha Suresh, Dave Bacon, 2016
- Gossip training for deep learning, Michael Blot and al., 2017
- Differentially Private Federated Learning: A Client Level Perspective Robin C. Geyer and al., 2018
- Konečný, Jakub; McMahan, H. Brendan; Yu, Felix X.; Richtárik, Peter; Suresh, Ananda Theertha; Bacon, Dave (30 October 2017). "Federated Learning: Strategies for Improving Communication Efficiency". arXiv:1610.05492 [cs].
- Amiri, Mohammad Mohammadi; Gunduz, Deniz (10 February 2020). "Federated Learning over Wireless Fading Channels". arXiv:1907.09769 [cs, math].
- "Federated Learning: Collaborative Machine Learning without Centralized Training Data". Google AI Blog. Archived from the original on 2020-01-30. Retrieved 2020-02-04.
- "Federated Learning: Machine Learning on Decentralized Data (Google I/O'19)". Youtube. Retrieved 25 June 2020.
- Xu, Jie; Wang, Fei (12 November 2019). "Federated Learning for Healthcare Informatics". arXiv:1911.06270 [cs].
- Choudhury, Olivia; Gkoulalas-Divanis, Aris; Salonidis, Theodoros; Sylla, Issa; Park, Yoonyoung; Hsu, Grace; Das, Amar (2020-02-27). "Differential Privacy-enabled Federated Learning for Sensitive Health Data". arXiv:1910.02578 [cs].
- Brisimi, Theodora S.; Chen, Ruidi; Mela, Theofanie; Olshevsky, Alex; Paschalidis, Ioannis Ch.; Shi, Wei (2018-04-01). "Federated learning of predictive models from federated Electronic Health Records". International Journal of Medical Informatics. 112: 59–67. doi:10.1016/j.ijmedinf.2018.01.007. ISSN 1386-5056.
- "Towards Efficient and Reliable Federated Learning Using Blockchain For Autonomous Vehicles". Computer Networks. 21 July 2020.
- Elbir, Ahmet M.; Coleri, S. (2 June 2020). "Federated Learning for Vehicular Networks". arXiv:2006.01412 [cs, eess, math].
- Cioffi, Raffaele; Travaglioni, Marta; Piscitelli, Giuseppina; Petrillo, Antonella; De Felice, Fabio (2019). "Artificial Intelligence and Machine Learning Applications in Smart Production: Progress, Trends, and Directions". Sustainability. 12 (2): 492. doi:10.3390/su12020492.
External links
- "Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016" at eur-lex.europa.eu. Retrieved October 18, 2019.
- "Data minimisation and privacy-preserving techniques in AI systems" at UK Information Commissioners Office. Retrieved July 22, 2020