Distributed Replicated Block Device
DRBD is a distributed replicated storage system for the Linux platform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts. DRBD is traditionally used in high availability (HA) computer clusters, but beginning with DRBD version 9, it can also be used to create larger software defined storage pools with a focus on cloud integration.[1]
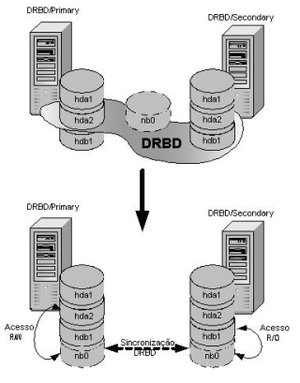 Overview of DRBD concept | |
| Original author(s) | Philipp Reisner, Lars Ellenberg |
|---|---|
| Developer(s) | LINBIT HA-Solutions GmbH, Vienna and LINBIT USA LLC, Oregon |
| Stable release | 9.0.17-1 (DRBD SDS), 8.4.11-1 (DRBD HA)
/ 26 March 2019 |
| Repository | |
| Written in | C |
| Operating system | Linux |
| Type | Distributed storage system |
| License | GNU General Public License v2 |
| Website | www |
A DRBD device is a DRBD block device that refers to a logical block device in a logical volume schema.
The DRBD software is free software released under the terms of the GNU General Public License version 2.
DRBD is part of the Lisog open source stack initiative.
Mode of operation
DRBD layers logical block devices (conventionally named /dev/drbdX, where X is the device minor number) over existing local block devices on participating cluster nodes. Writes to the primary node are transferred to the lower-level block device and simultaneously propagated to the secondary node(s). The secondary node(s) then transfers data to its corresponding lower-level block device. All read I/O is performed locally unless read-balancing is configured.[2]
Should the primary node fail, a cluster management process promotes the secondary node to a primary state.[3] This transition may require a subsequent verification of the integrity of the file system stacked on top of DRBD, by way of a filesystem check or a journal replay. When the failed ex-primary node returns, the system may (or may not) raise it to primary level again, after device data resynchronization. DRBD's synchronization algorithm is efficient in the sense that only those blocks that were changed during the outage must be resynchronized, rather than the device in its entirety.
DRBD is often deployed together with the Pacemaker or Heartbeat cluster resource managers, although it does integrate with other cluster management frameworks. It integrates with virtualization solutions such as Xen, and may be used both below and on top of the Linux LVM stack.[4]
DRBD allows for load-balancing configurations, allowing both nodes to access a particular DRBD in read/write mode with shared storage semantics.[5] A multiple primary (multiple read/write nodes) configuration requires the use of a distributed lock manager.
Shared cluster storage comparison
Conventional computer cluster systems typically use some sort of shared storage for data being used by cluster resources. This approach has a number of disadvantages, which DRBD may help offset:
- Shared storage resources must typically be accessed over a storage area network or on a network attached storage server, which creates some overhead in read I/O. In DRBD that overhead is reduced as all read operations are carried out locally.
- Shared storage is usually expensive and consumes more space (2U and more) and power. DRBD allows for an HA setup with only 2 machines.
- Shared storage is not necessarily highly available. For example, a single storage area network accessed by multiple virtualization hosts is considered shared storage, but is not considered highly available at the storage level - if that single storage area network fails, neither host within the cluster can access the shared storage. DRBD allows for a storage target that is both shared and highly available.
A disadvantage is the lower time required to write directly to a shared storage device than to route the write through the other node.
Comparison to RAID-1
DRBD bears a superficial similarity to RAID-1 in that it involves a copy of data on two storage devices, such that if one fails, the data on the other can be used. However, it operates in a very different way from RAID and even network RAID.
In RAID, the redundancy exists in a layer transparent to the storage-using application. While there are two storage devices, there is only one instance of the application and the application is not aware of multiple copies. When the application reads, the RAID layer chooses the storage device to read. When a storage device fails, the RAID layer chooses to read the other, without the application instance knowing of the failure.
In contrast, with DRBD there are two instances of the application, and each can read only from one of the two storage devices. Should one storage device fail, the application instance tied to that device can no longer read the data. Consequently, in that case that application instance shuts down and the other application instance, tied to the surviving copy of the data, takes over.
Conversely, in RAID, if the single application instance fails, the information on the two storage devices is effectively unusable, but in DRBD, the other application instance can take over.
Applications
Operating within the Linux kernel's block layer, DRBD is essentially workload agnostic. A DRBD can be used as the basis of
- A conventional file system (this is the canonical example),
- a shared disk file system such as GFS2 or OCFS2,[6][7]
- another logical block device (as used in LVM, for example),
- any application requiring direct access to a block device.
DRBD-based clusters are often employed for adding synchronous replication and high availability to file servers, relational databases (such as MySQL), and many other workloads.
Inclusion in Linux kernel
DRBD's authors originally submitted the software to the Linux kernel community in July 2007, for possible inclusion in the canonical kernel.org version of the Linux kernel.[8] After a lengthy review and several discussions, Linus Torvalds agreed to have DRBD as part of the official Linux kernel. DRBD was merged on 8 December 2009 during the "merge window" for Linux kernel version 2.6.33.
References
- "DRBD for your Cloud". www.drbd.org. Retrieved 2016-12-05.
- "18.4. Achieving better Read Performance via increased Redundancy - DRBD Users Guide (9.0)". www.drbd.org. Retrieved 2016-12-05.
- "Chapter 8. Integrating DRBD with Pacemaker clusters - DRBD Users Guide (9.0)". www.drbd.org. Retrieved 2016-12-05.
- LINBIT. "The DRBD User's Guide". Retrieved 2011-11-28.
- Reisner, Philipp (2005-10-11). "DRBD v8 - Replicated Storage with Shared Disk Semantics" (PDF). Proceedings of the 12th International Linux System Technology Conference. Hamburg, Germany.
- http://www.drbd.org/users-guide/ch-ocfs2.html
- "Archived copy". Archived from the original on 2013-03-08. Retrieved 2013-03-21.CS1 maint: archived copy as title (link)
- Ellenberg, Lars (2007-07-21). "DRBD wants to go mainline". linux-kernel (Mailing list). Retrieved 2007-08-03.
External links
| Wikimedia Commons has media related to DRBD. |
| Linux kernel | |
|---|---|
| Controversies | |
| Distributions | |
| Organizations | |
| Adoption |
|
| Media | |
| |