Bacterial one-hybrid system
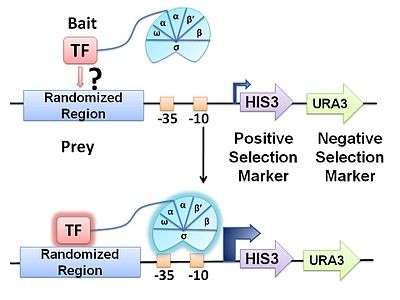
The bacterial one-hybrid (B1H) system is a method for identifying the sequence-specific target site of a DNA-binding domain. In this system, a given transcription factor (TF) is expressed as a fusion to a subunit of RNA polymerase. In parallel, a library of randomized oligonucleotides representing potential TF target sequences are cloned into a separate vector containing the selectable genes HIS3 and URA3. If the DNA-binding domain (bait) binds a potential DNA target site (prey) in vivo, it will recruit RNA polymerase to the promoter and activate transcription of the reporter genes in that clone. The two reporter genes, HIS3 and URA3, allow for positive and negative selections, respectively. At the end of the process, positive clones are sequenced and examined with motif-finding tools in order to resolve the favoured DNA target sequence.[1]
Introduction
Across all living organisms, regulation of gene expression is controlled by interactions between DNA-binding regulatory proteins (transcription factors) and cis-regulatory elements, DNA sequences in or around genes that act as target sites for DNA-binding proteins. By binding to cis-regulatory sequences and to each other, transcription factors fine-tune transcriptional levels by stabilizing/destabilizing binding of RNA polymerase to a gene's promoter. But despite their importance and ubiquity, little is known about where exactly each of these regulatory proteins binds. Literature suggests that nearly 8% of human genes encode transcription factors and the functions and specificities of their interactions remain largely unexplored.[2] We are on the brink of a convergence of high-throughput technologies and genomic theory that is allowing researchers to start mapping these interactions on a genome-wide scale. Only recently has a complete survey of DNA-binding specificities been attempted for a large family of DNA-binding domains. B1H is just one emerging technique among many that is useful for studying protein–DNA interactions.[3]
Method overview
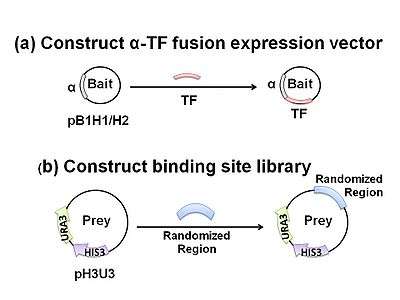
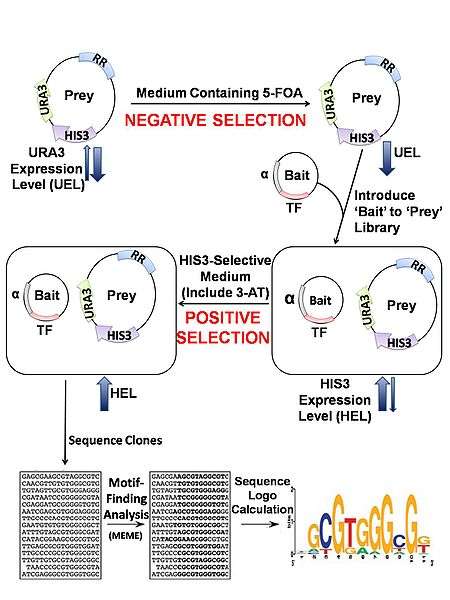
Transformation of a bacterial host with two different plasmids is required. One is designed to express a DNA-binding protein-of-interest as a fusion construct with a subunit of RNA polymerase (bait). The other plasmid contains a region of randomized sequence representing potential binding sites (prey) which, if bound to by the chimeric fusion product, drives expression of downstream reporter genes. This reporter region facilitates both positive and negative selection by HIS3 and URA3, respectively, which together allow for isolation of the prey containing the true DNA target sequence. HIS3 and URA3 encode proteins required for biosynthesis of histidine and uracil.
Using a negative selectable marker is crucial for greatly reducing the incidence of false-positives. Self-activating prey, where the randomized region facilitate reporter expression in the absence of TF binding, are removed by transforming the reporter vector library into bacteria in the absence of bait and assaying for growth on plates containing 5-fluoro-orotic acid (5-FOA). The protein product of URA3 converts 5-FOA into a toxic compound, thereby allowing survival of only those colonies that contain reporter vectors which are not self-activating. Negative selection normally precedes positive selection so that a smaller, purified prey library can be subjected to the more rigorous positive selection process. Upon transformation of the purified prey library with the bait plasmid, positive selection is achieved by growing the host E. coli on minimal medium lacking histidine (NM selective medium) that is usually supplemented with varying concentrations of 3-amino-triazole (3-AT), a competitive inhibitor of HIS3. HIS3 encodes a protein required for histidine biosynthesis and thus only those cells containing bait-prey combinations that activate the reporter genes will be able to grow. Manipulating 3-AT concentrations allows for the characterization of binding stringencies. In this way, researches can gauge how strongly bait binds its prey (correlated with the level of expression of HIS3) and thus determines which nucleotide binding-sites have strong or weak preferences for a given base. In other words, if cells can grow despite a high concentration of 3-AT, bait-prey binding must be of high enough stringency to drive reporter gene expression (HIS3) at a sufficient level to overcome the resulting competitive inhibition. Finally, positive clones are sequenced and examined with preexisting motif-finding tools (ex, MEME, BioProspector).[3]
History of method
The bacteria one-hybrid system has undergone numerous modifications since its inception in 2005.[3] It ultimately arose as a variation of the bacteria two-hybrid system, conceived in 2000, which itself was inspired by the yeast one- and two-hybrid systems.[4] Whereas the two-hybrid versions can assess both protein–protein interaction and protein–DNA interactions, the one-hybrid system specializes in the latter. Meng et al.’s B1H system differs from the two-hybrid version in two key respects. It uses a randomized prey library consisting of many (<2x108) unique potential target sequences and also adds a negative selection step in order to purge this library of self-activating clones.[1][3] Although these ideas were borrowed from the original yeast one-hybrid system,[5] they had not yet been applied to a bacterial host before 2005. As the technique grew in popularity, researchers amended their protocols to improve the B1H system. Designing the fusion construct (bait) to the omega, rather than the alpha, subunit of RNA polymerase has recently been favoured in order to improve the chimera’s stereochemistry and dynamic range.[6] A zinc-finger domain on the fusion construct and its corresponding DNA target site, adjacent to the randomized prey sequence, has also been added to the increases affinity and specificity of protein–DNA interactions. This increased overall binding affinity allows for the characterization of even those DNA-binding domain proteins which interact weakly with a target sequence.[7]
.
Advantages
The B1H system has significant advantages over other methods that investigate protein–DNA interactions. Microarray-based readout of chromatin immunoprecipitation (ChIP-chip) for high-throughput binding-site determination relies on specific antibodies which may not always be available. Methods that rely on protein-binding microarrays also require additional protein purification steps that are not required in the B1H system. Furthermore, these microarray-based techniques are often prohibitive in terms of requiring special facilities and expertise to analyze the resulting data. SELEX, another system commonly used to identify the target nucleic acids for DNA-binding proteins, requires multiple rounds of selection. In contrast, the bacterial one-hybrid system requires just one round of in vitro selection and also offers a low-tech alternative to microarray-based technologies. Antibodies are not required for studying the interactions of DNA-binding proteins in the B1H system. A further advantage is that the B1H system works not only for monomeric proteins but also for proteins that bind DNA as complexes. The B1H system should be considered a specialized technique for studying DNA-protein interactions whereas the two-hybrid variations (B2H and Y2H) can assess both protein–protein and protein–DNA interactions. These two-hybrid systems are multi-purpose but are limited in terms of assaying only a single “prey” library. An advantage of the bacterial one-hybrid system over the yeast one-hybrid system (Y1H) lies in the higher transformation efficiency of plasmids into bacteria which allows for more complex “prey” libraries to be examined.[1][3]
Limitations
Despite its aforementioned advantages as a specialized tool, the B1H system does have some drawbacks. First, the B1H selection system is limited in its capacity to determine the binding specificities of transcription factors with lengthy binding sites. This arises from the fact that the number of randomized “prey” clones required to represent all possible target sequences increases exponentially with the number of nucleotides in that target sequence. Second, some eukaryotic factors may not express or fold efficiently in the bacterial system, attributed to differing regulatory networks and transcriptional machinery. Hence when working with DNA-binding proteins of eukaryotic origin, a yeast-based hybrid system may be beneficial. Third, the B1H system may not be ideally suited for transcription factors that recognize binding sites with low affinity. The logic here is that competition created by binding sites elsewhere in the bacterial genome may limit the signal that can be realized from a single binding site that is present upstream of the reporter.[1][3]
Application
B1H system provides a tool in our arsenal for identifying the DNA-binding specificities of transcription factors and thus predicting their target genes and genomic DNA regulatory elements. It also allows for examination of the effects of protein–protein interactions on DNA binding, which may further guide the prediction of cis regulatory modules based on binding-site clustering. Moreover, the B1H selection system has implications for the predicting regulatory roles of previously uncharacterized transcription factors.[1]
Specific examples
Using the bacterial one-hybrid system, one study has characterized 35 members of the Drosophilia melanogaster segmentation network which includes representative members of all the major classes of DNA-binding domain proteins.[8] Implications for medical research are evident from another study that used the B1H system to identify the DNA-binding specificity of a transcriptional regulator for a gene in Mycobacterium tuberculosis.[9] The B1H system has also been used to identify an important turnover element in Escherichia coli.[10]
External links
- https://web.archive.org/web/20090320023431/http://lawsonlab.umassmed.edu/PDFs/B1HStart.pdf
- http://www.umassmed.edu/pgfe/faculty/wolfe.cfm?start=0&
| Wikimedia Commons has media related to Bacterial one-hybrid system. |
References
- Bulyk M (2005). "Discovering DNA regulatory elements with bacteria". Nature Biotechnology. 23 (8): 942–944. doi:10.1038/nbt0805-942. PMC 2720157. PMID 16082362.
- Messina DN, Glasscock J, Gish W, Lovett M (2004). "An ORFeome-based Analysis of Human Transcription Factor Genes and the Construction of a Microarray to Interrogate Their Expression". Genome Research. 14 (2004): 2041–2047. doi:10.1101/gr.2584104. ISSN 1088-9051. PMC 528918. PMID 15489324.
- Meng X, Wolfe SA (2006). "Identifying DNA sequences recognized by a transcription factor using a bacterial one-hybrid system". Nature Protocols. 1 (1): 30–45. doi:10.1038/nprot.2006.6. PMID 17406209.
- Joung JK, Ramm EL, Pabo CO (2000). "A bacterial two-hybrid selection system for studying protein–DNA and protein–protein interactions". PNAS. 97 (13): 7382–7387. doi:10.1073/pnas.110149297. PMC 16554. PMID 10852947.
- Wilson TE, Fahrner TJ, Johnston M, Milbrant J (1991). "Identifying of the DNA binding site for NGFI-B by genetic selection in yeast". Science. 252 (5010): 1296–1300. doi:10.1126/science.1925541. PMID 1925541.
- Noyes MB, Christensen RG, Wakabayashi A, Stormo GD, Brodsky MH, Wolfe SA (2006). "Analysis of Homeodomain Specificities Allows the Family-wide Prediction of Preferred Recognition Sites". Cell. 133 (2008): 1277–1289. doi:10.1016/j.cell.2008.05.023. PMC 2478728. PMID 18585360.
- Durai S, Bosley A, Abulencia AB, Chandrasegaran S, Ostermeier M (2006). "A bacterial One-Hybrid Selection System for Interrogating Zinc Fingure_DNA Interactions". Combinatorial Chemistry & High Throughput Screening. 9 (2006): 301–311. doi:10.2174/138620706776843147.
- Noyes MB, Meng X, Wakabayashi A, Sinha S, Brodsky MH, Wolfe SA (2008). "A systematic characterization of factors that regulate Drosophila segmentation via a bacterial one-hybrid System". Nucleic Acids Research. 36 (8): 2547–2560. doi:10.1093/nar/gkn048. PMC 2377422. PMID 18332042.
- Guo M, Feng H, Zhang J, Wang W, Wang J, Li Y, Gao C, Chen H, Feng Y, He ZG (2009). "Dissecting transcription regulatory pathways through a new bacterial one-hybrid reporter system". Genome Research. 19 (7): 1301–8. doi:10.1101/gr.086595.108. PMC 2704442. PMID 19228590.
- Obrist M, Narberhaus F (2005). "Identification of a Turnover Element in Region 2.1 of Escherichia coli 32 by a Bacterial One-Hybrid Approach". Journal of Bacteriology. 187 (11): 3807–3813. doi:10.1128/JB.187.11.3807-3813.2005. PMC 1112070. PMID 15901705.