Auditory scene analysis
In perception and psychophysics, auditory scene analysis (ASA) is a proposed model for the basis of auditory perception. This is understood as the process by which the human auditory system organizes sound into perceptually meaningful elements. The term was coined by psychologist Albert Bregman.[1] The related concept in machine perception is computational auditory scene analysis (CASA), which is closely related to source separation and blind signal separation.
The three key aspects of Bregman's ASA model are: segmentation, integration, and segregation.
Background
Sound reaches the ear and the eardrum vibrates as a whole. This signal has to be analyzed (in some way). Bregman's ASA model proposes that sounds will either be heard as "integrated" (heard as a whole – much like harmony in music), or "segregated" into individual components (which leads to counterpoint). For example, a bell can be heard as a 'single' sound (integrated), or some people are able to hear the individual components – they are able to segregate the sound. This can be done with chords where it can be heard as a 'color', or as the individual notes. Natural sounds, such as the human voice, musical instruments, or cars passing in the street, are made up of many frequencies, which contribute to the perceived quality (like timbre) of the sounds. When two or more natural sounds occur at once, all the components of the simultaneously active sounds are received at the same time, or overlapped in time, by the ears of listeners. This presents their auditory systems with a problem: which parts of the sound should be grouped together and treated as parts of the same source or object? Grouping them incorrectly can cause the listener to hear non-existent sounds built from the wrong combinations of the original components.
In many circumstances the segregated elements can be linked together in time, producing an auditory stream. This ability of auditory streaming can be demonstrated by the so-called cocktail party effect. Up to a point, with a number of voices speaking at the same time or with background sounds, one is able to follow a particular voice even though other voices and background sounds are present.[2] In this example, the ear is segregating this voice from other sounds (which are integrated), and the mind "streams" these segregated sounds into an auditory stream. This is a skill which is highly developed by musicians, notably conductors who are able to listen to one, two, three or more instruments at the same time (segregating them), and following each as an independent line through auditory streaming.
Grouping and streams
A number of grouping principles appear to underlie ASA, many of which are related to principles of perceptual organization discovered by the school of Gestalt psychology. These can be broadly categorized into sequential grouping mechanisms (those that operate across time) and simultaneous grouping mechanisms (those that operate across frequency):
- Errors in simultaneous grouping can lead to the blending of sounds that should be heard as separate, the blended sounds having different perceived qualities (such as pitch or timbre) to any of the sounds actually received. For instance two vowels presented simultaneously may not be identifiable if they are segregated.[3]
- Errors in sequential grouping can lead, for example, to hearing a word created out of syllables originating from two different voices.[4][5]
Segregation can be based primarily on perceptual cues or rely on the recognition of learned patterns ("schema-based").
The job of ASA is to group incoming sensory information to form an accurate mental representation of the individual sounds. When sounds are grouped by the auditory system into a perceived sequence, distinct from other co-occurring sequences, each of these perceived sequences is called an "auditory stream". In the real world, if the ASA is successful, a stream corresponds to a distinct environmental sound source producing a pattern that persists over time, such as a person talking, a piano playing, or a dog barking. However, in the lab, by manipulating the acoustic parameters of the sounds, it is possible to induce the perception of one or more auditory streams.
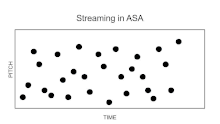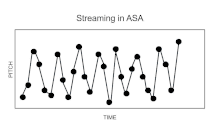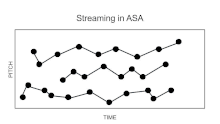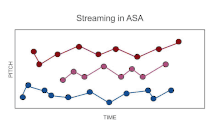
One example of this is the phenomenon of streaming, also called "stream segregation."[6] If two sounds, A and B, are rapidly alternated in time, after a few seconds the perception may seem to "split" so that the listener hears two rather than one stream of sound, each stream corresponding to the repetitions of one of the two sounds, for example, A-A-A-A-, etc. accompanied by B-B-B-B-, etc. The tendency towards segregation into separate streams is favored by differences in the acoustical properties of sounds A and B. Among the differences classically shown to promote segregation are those of frequency (for pure tones), fundamental frequency (for complex tones), frequency composition, source location. But it has been suggested that about any systematic perceptual difference between two sequences can elicit streaming,[7] provided the speed of the sequence is sufficient.
An interactive web page illustrating this streaming and the importance of frequency separation and speed can be found here.
Experimental basis
Many experiments have studied the segregation of more complex patterns of sound, such as a sequence of high notes of different pitches, interleaved with low ones. In such sequences, the segregation of co-occurring sounds into distinct streams has a profound effect on the way they are heard. Perception of a melody is formed more easily if all its notes fall in the same auditory stream. We tend to hear the rhythms among notes that are in the same stream, excluding those that are in other streams. Judgments of timing are more precise between notes in the same stream than between notes in separate streams. Even perceived spatial location and perceived loudness can be affected by sequential grouping.
While the initial research on this topic was done on human adults, recent studies have shown that some ASA capabilities are present in newborn infants, showing that they are built-in, rather than learned through experience. Other research has shown that non-human animals also display ASA. Currently, scientists are studying the activity of neurons in the auditory regions of the cerebral cortex to discover the mechanisms underlying ASA.
References
- Bregman, A. S. (1990) Auditory scene analysis. MIT Press: Cambridge, MA
- Miller, G. A. (1947). "The masking of speech". Psychological Bulletin. 44 (2): 105–129. doi:10.1037/h0055960. PMID 20288932.
- Assmann, P. F.; Summerfield, Q. (August 1990). "Modeling the perception of concurrent vowels: Vowels with different fundamental frequencies". The Journal of the Acoustical Society of America. 88 (2): 680–697. Bibcode:1990ASAJ...88..680A. doi:10.1121/1.399772. PMID 2212292.
- Gaudrain, E.; Grimault, N.; Healy, E. W.; Béra, J.-C. (2007). "Effect of spectral smearing on the perceptual segregation of vowel sequences". Hearing Research. 231 (1–2): 32–41. doi:10.1016/j.heares.2007.05.001. PMC 2128787. PMID 17597319.
- Billig, A. J.; Davis, M. H.; Deeks, J. M.; Monstrey, J.; Carlyon, R. P. (2013). "Lexical Influences on Auditory Streaming". Current Biology. 23 (16): 1585–1589. doi:10.1016/j.cub.2013.06.042. PMC 3748342. PMID 23891107.
- van Noorden, L. P. A. S. (1975). Temporal coherence in the perception of tones sequences (PDF) (PhD). The Netherlands: Eindhoven University of Technology. Retrieved 10 March 2018.
- Moore, B. C. J.; Gockel, H. E. (2012). "Properties of auditory stream formation". Philosophical Transactions of the Royal Society B: Biological Sciences. 367 (1591): 919–931. doi:10.1098/rstb.2011.0355. PMC 3282308. PMID 22371614.