2
I had setup two 500gb disk in RAID0 on my server, but recently suffered a hard disk failure (saw a S.M.A.R.T error on the HDD at boot). My host has put 2 new disk in RAID-0 again (re-installed the OS) and re-attached the old drives on the same machine, so that I can recover the data.
My old drives are:
/dev/sdb/dev/sdc
How can I mount these two disks back in RAID0, so that we can recover the data from our old drive? Or is this not possible any more? Have I lost all my data?
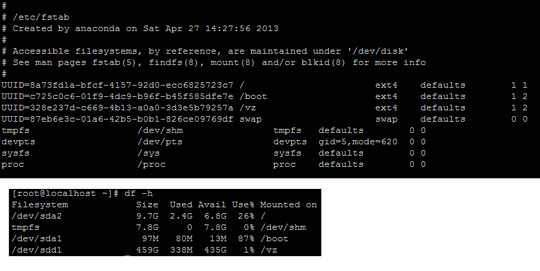
This is my /etc/fstab and df -h
This is my fdisk -l:
[root@localhost ~]# fdisk -l
Disk /dev/sda: 500.1 GB, 500107862016 bytes
255 heads, 63 sectors/track, 60801 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00040cf1
Device Boot Start End Blocks Id System
/dev/sda1 * 1 13 102400 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 13 1288 10240000 83 Linux
/dev/sda3 1288 2333 8388608 82 Linux swap / Solaris
Disk /dev/sdc: 500.1 GB, 500107862016 bytes
255 heads, 63 sectors/track, 60801 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0005159c
Device Boot Start End Blocks Id System
/dev/sdc1 1 60802 488385536 fd Linux raid autodetect
Disk /dev/sdb: 500.1 GB, 500107862016 bytes
255 heads, 63 sectors/track, 60801 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0006dd55
Device Boot Start End Blocks Id System
/dev/sdb1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sdb2 26 4106 32768000 82 Linux swap / Solaris
/dev/sdb3 4106 5380 10240000 83 Linux
/dev/sdb4 5380 60802 445172736 5 Extended
/dev/sdb5 5380 60802 445171712 fd Linux raid autodetect
Disk /dev/sdd: 500.1 GB, 500107862016 bytes
255 heads, 63 sectors/track, 60801 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x9f639f63
Device Boot Start End Blocks Id System
/dev/sdd1 1 60802 488385536 83 Linux
Disk /dev/md127: 956.0 GB, 955960524800 bytes
2 heads, 4 sectors/track, 233388800 cylinders
Units = cylinders of 8 * 512 = 4096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 524288 bytes / 1048576 bytes
Disk identifier: 0x00000000
I read somewhere that you can do this with this command: mdadm -A --scan however, it does not yield any result for me -> No arrays found in config file or automatically

Latheesan
Posted 2013-04-29T14:11:48.890
Reputation: 113

Two years later, and I found this discussion. In my case, I had two 1T RAID 1 drives from a decommissioned server that I plugged into a 2 bay dock. On Ubuntu 15.10, I ran mdadm - A --scan and, presto, a cluster was built allowing me full access to the data. I've upvoted the discussion. Thanks! – tim.rohrer – 2015-11-12T14:44:26.037
What is the output of
mdadm --examine /dev/sdbandmdadm --examine /dev/sdc? – Darth Android – 2013-04-29T14:14:28.657Also, what is the output of
cat /proc/mdstat? – Darth Android – 2013-04-29T14:24:39.717Just realized, you probably want to
mdadm --examinethe/dev/sdb5and/dev/sdc1partitions instead of the drives themselves. – Darth Android – 2013-04-29T14:36:00.197I've examined it and here's the result: http://pastebin.com/raw.php?i=nnFzw0GG
– Latheesan – 2013-04-29T21:48:22.353Uh, what's the output of
cat /proc/mdstat? That pastebin says that your old array is functioning just fine and is 100% clean - in fact, the reason you can't assemble the array is because it's already assembled. Trymkdir /mnt/oldData && mount /dev/md127 /mnt/oldData. That said, if one of the drives was giving a SMART error, I wouldn't trust the drive any more, and would still back up all of the data off of it. – Darth Android – 2013-04-29T22:42:43.820Your new drives are not currently in
RAID0. One drive is mounted to/, and the other drive is mounted to/vz– Darth Android – 2013-04-29T22:44:43.767@DarthAndroid - This is the output of
cat /proc/mdstat- http://pastebin.com/raw.php?i=7CcVSbQXI am going to try and mount it and see if it works. Thanks for the suggestion.
@DarthAndroid - I think you are right, our host has not even put 2 new disk back in RAID0, they literally put 1 disk and split it into two partition (one at / root and another at /vz ) - I will complain about this momentarily. My concern now is getting the data back. – Latheesan – 2013-04-30T11:03:56.767
@DarthAndroid - Thanks for recommending this
mkdir /mnt/oldData && mount /dev/md127 /mnt/oldData- IT WORKED !!! – Latheesan – 2013-04-30T11:06:55.887Awesome! I'd get a backup of the data moved to non-RAIDed disks ASAP, preferably even a local computer before your provider starts messing with the disks again, so that you're not at the mercy of their ability to do what they say. – Darth Android – 2013-04-30T16:29:15.700