We currently have five 24 port 3com unmanaged switches. Four of them are 100Mb switches with no gigabit port (MDI Uplink port is 100Mb). The fifth is a full gigabit switch which we use for all of our servers. They are daisy chained together at the moment, kind of like this:
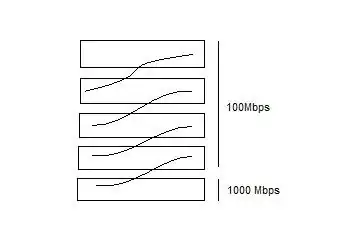
At certain times of the day, network performance becomes atrocious. We've verified that this has nothing to do with server capacity, so we're left with considering network I/O bottlenecks. We were hoping to connect each 100Mb switch directly to the gigabit switch so that each user would only be 1 switch away from the server ... like this:
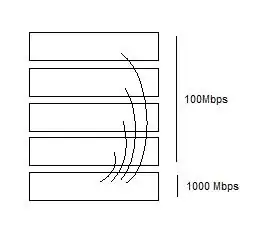
The moment this was connected, all network traffic stopped. Is this the wrong way to do it? We verified that no loops exist, and verified that we didn't have any crossover cables (all switches have Auto-MDI). Power cycling the 5 switches didn't do anything either.