There are many compression algorithms around, and bzip2 is one of the slower ones. Plain gzip tends to be significantly faster, at usually not much worse compression. When speed is the most important, lzop is my favourite. Poor compression, but oh so fast.
I decided to have some fun and compare a few algorithms, including their parallel implementations. The input file is the output of pg_dumpall command on my workstation, a 1913 MB SQL file. The hardware is an older quad-core i5. The times are wall-clock times of just the compression. Parallel implementations are set to use all 4 cores. Table sorted by compression speed.
Algorithm Compressed size Compression Decompression
lzop 398MB 20.8% 4.2s 455.6MB/s 3.1s 617.3MB/s
lz4 416MB 21.7% 4.5s 424.2MB/s 1.6s 1181.3MB/s
brotli (q0) 307MB 16.1% 7.3s 262.1MB/s 4.9s 390.5MB/s
brotli (q1) 234MB 12.2% 8.7s 220.0MB/s 4.9s 390.5MB/s
zstd 266MB 13.9% 11.9s 161.1MB/s 3.5s 539.5MB/s
pigz (x4) 232MB 12.1% 13.1s 146.1MB/s 4.2s 455.6MB/s
gzip 232MB 12.1% 39.1s 48.9MB/s 9.2s 208.0MB/s
lbzip2 (x4) 188MB 9.9% 42.0s 45.6MB/s 13.2s 144.9MB/s
pbzip2 (x4) 189MB 9.9% 117.5s 16.3MB/s 20.1s 95.2MB/s
bzip2 189MB 9.9% 273.4s 7.0MB/s 42.8s 44.7MB/s
pixz (x4) 132MB 6.9% 456.3s 4.2MB/s 7.9s 242.2MB/s
xz 132MB 6.9% 1027.8s 1.9MB/s 17.3s 110.6MB/s
brotli (q11) 141MB 7.4% 4979.2s 0.4MB/s 3.6s 531.6MB/s
If the 16 cores of your server are idle enough that all can be used for compression, pbzip2 will probably give you a very significant speed-up. But you need more speed still and you can tolerate ~20% larger files, gzip is probably your best bet.
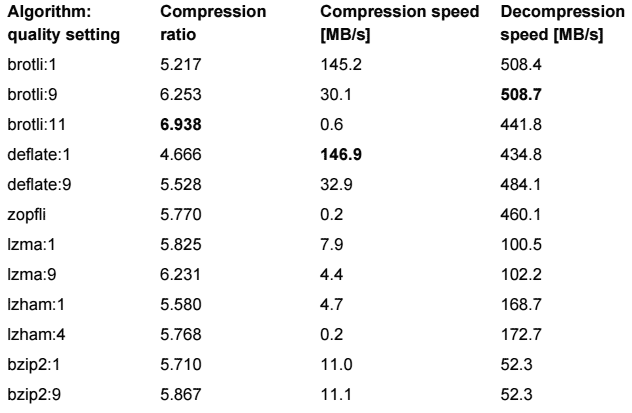
Update: I added brotli (see TOOGAMs answer) results to the table. brotlis compression quality setting has a very large impact on compression ratio and speed, so I added three settings (q0, q1, and q11). The default is q11, but it is extremely slow, and still worse than xz. q1 looks very good though; the same compression ratio as gzip, but 4-5 times as fast!
Update: Added lbzip2 (see gmathts comment) and zstd (Johnny's comment) to the table, and sorted it by compression speed. lbzip2 puts the bzip2 family back in the running by compressing three times as fast as pbzip2 with a great compression ratio! zstd also looks reasonable but is beat by brotli (q1) in both ratio and speed.
My original conclusion that plain gzip is the best bet is starting to look almost silly. Although for ubiquity, it still can't be beat ;)
{kind=link}
{kind=link}