I am working on a proposal for a system with seven CouchDB servers (A,B,C,D,E,F,G) in different countries. The idea is to configure multi-master replication so that all data can be kept in sync.
I could configure bi-directional replication from each server to each other server
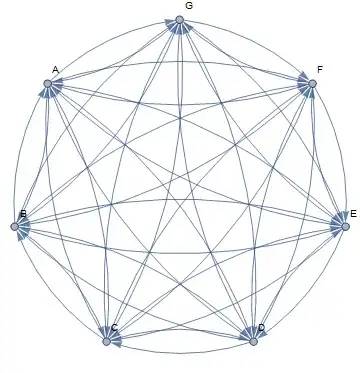
but I suspect that this may result in too many connections that could reduce performance by increasing the used bandwidth (is this the case?).
So my next idea is to configure them like a ring:
Now we have much fewer connections and still have redundancy as each node is connected to two servers. The problem for my particular situation is that we don't want to have all databases in all the nodes. We would like to have two nodes (A & B) with all the databases and the rest with different subsets of it. For this reason I am thinking about doing this:
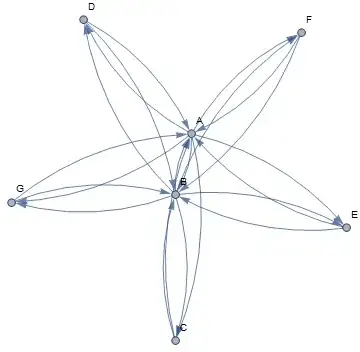
As I am not a network topology expert, I would like to ask:
- Is it truly not a good idea to replicate all nodes against all nodes?
- Is this a reasonable topology (the last shown)?
- Where could I learn more about this?
Just for completeness, the figures were generated with the following Mathematica commands:
Graph[Rule @@@ Permutations[CharacterRange["A", "G"], {2}], VertexLabels -> "Name"]
Graph[Rule @@@ (Partition[CharacterRange["A", "G"], 2, 1, {-1}] /. {a_, b_} :> Sequence[{a, b}, {b, a}]), VertexLabels -> "Name"]
Graph[Flatten[Outer[{#1 -> #2, #2 -> #1} &, {"A", "B"}, CharacterRange["C", "G"]]~Join~{"A" -> "B", "B" -> "A"}], VertexLabels -> "Name"]