I'm experimenting with deduplication on a Server 2012 R2 storage space. I let it run the first dedupe optimisation last night, and I was pleased to see that it claimed a 340GB reduction.

However, I knew that this was too good to be true. On that drive, 100% of the dedupe came from SQL Server backups:
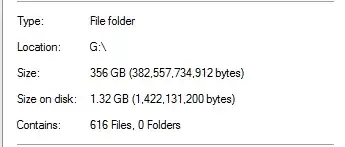
That seems unrealistic, considering that there are databases backups that are 20x that size in the folder. As an example:
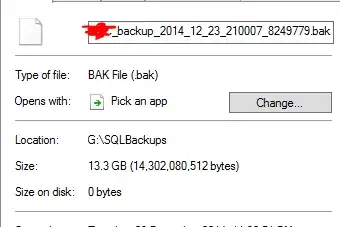
It reckons that a 13.3GB backup file has been deduped to 0 bytes. And of course, that file doesn't actually work when I did a test restore of it.
To add insult to injury, there is another folder on that drive that has almost a TB of data in it that should have deduped a lot, but hasn't.
Does Server 2012 R2 deduplication work?