Update 4,215:
After looking at space usage inside of hdfs, I see that .oldlogs is using a lot of space:
1485820612766 /hbase/.oldlogs
So new questions:
- What is it?
- How do I clean it up?
- How do I keep it from growing again
- What caused it to start growing in the first place?
- Also .archive is big too, what is that, my snapshots?
Also as homework scollector will no monitor the disk space usage of various hdfs directories....
Also looks like the following error started filling the logs repeatedly around that time, not sure what they mean exactly:
2014-11-25 01:44:47,673 FATAL org.apache.hadoop.hbase.regionserver.wal.HLog: Could not sync. Requesting close of hlog
java.io.IOException: Reflection
at org.apache.hadoop.hbase.regionserver.wal.SequenceFileLogWriter.sync(SequenceFileLogWriter.java:310)
at org.apache.hadoop.hbase.regionserver.wal.HLog.syncer(HLog.java:1405)
at org.apache.hadoop.hbase.regionserver.wal.HLog.syncer(HLog.java:1349)
at org.apache.hadoop.hbase.regionserver.wal.HLog.sync(HLog.java:1511)
at org.apache.hadoop.hbase.regionserver.wal.HLog$LogSyncer.run(HLog.java:1301)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor30.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.hbase.regionserver.wal.SequenceFileLogWriter.sync(SequenceFileLogWriter.java:308)
... 5 more
Caused by: java.io.IOException: Failed to add a datanode. User may turn off this feature by setting dfs.client.block.write.replace-datanode-on-failure.policy in configuration, where the current policy is DEFAULT. (Nodes: current=[10.7.0.231:50010, 10.7.0.233:50010], original=[10.7.0.231:50010, 10.7.0.233:50010])
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.findNewDatanode(DFSOutputStream.java:857)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.addDatanode2ExistingPipeline(DFSOutputStream.java:917)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1023)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.processDatanodeError(DFSOutputStream.java:821)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:463)
2014-11-25 01:44:47,673 ERROR org.apache.hadoop.hbase.regionserver.wal.HLog: Error while syncing, requesting close of hlog
My Journey:
On my HBASE cluster that stores openTSBD data, my diskspace started to climb rather rapidly (even though from what I can tell our insert rate has been consistent):
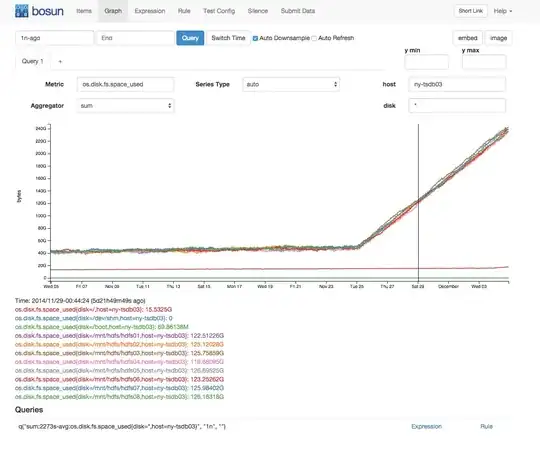
The disks that are increasing are the HDFS storage disks. The directories are roughly evenly sized.
My setup is a HBASE cluster (made with cloudera) that has 3 machines with an hdfs replication factor of 3. There is also another cluster with a single machine that the main cluster replicates to. The replica doesn't show this same change in growth:
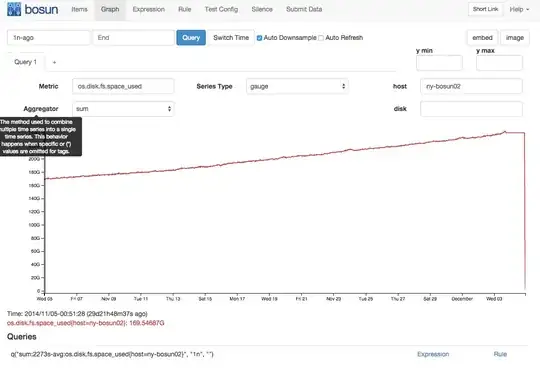
I am taking snapshots on the master, but list_snapshots from hbase shell doesn't show any going back more than a day, so I think those are being culled as they should be. My hbase experience isn't great, any suggestions on what else to look at?
Making Progress...:
[root@ny-tsdb01 ~]# hadoop fs -dus /hbase/*
dus: DEPRECATED: Please use 'du -s' instead.
3308 /hbase/-ROOT-
377401 /hbase/.META.
220097161480 /hbase/.archive
0 /hbase/.corrupt
1537972074 /hbase/.logs
1485820612766 /hbase/.oldlogs
8948367 /hbase/.snapshot
0 /hbase/.tmp
38 /hbase/hbase.id
3 /hbase/hbase.version
192819186494 /hbase/tsdb
905 /hbase/tsdb-meta
899 /hbase/tsdb-tree
1218051 /hbase/tsdb-uid