I'm running a load test against a web service. It's a php application running on php-fpm and nginx, with fastcgi. There is a MySQL backend being used for small reads only.
Invariably, I'm seeing a peculiar pattern: performance is steady and increases predictably as traffic ramps up, but then it becomes unstable right at the peak: the CPU usage fluctuates constantly.
Here is the performance pattern I'm seeing (visualised with nmon):
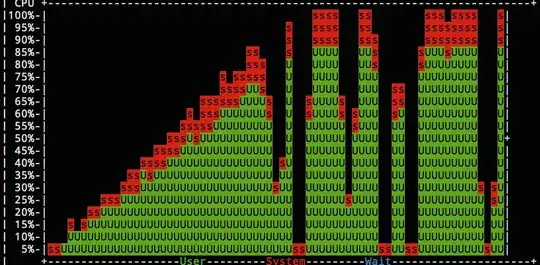
The drop-off always coincides with the brief pause that my load testing tool - locust.io - has when it finishes ramping up to the peak level I've set for the test.
My hypothesis: During this brief moment, the php-fpm master thinks that the load has disappeared and start to kill workers; it's not able to respond quickly enough when the traffic comes back in full swing a moment later.
What I don't quite understand is why it's never quite able to get back into the swing of it: I see this fluctuation indefinitely across all 4 application servers behind the load balancer.
Here is my php-fpm pool config:
[www]
user = www-data
group = www-data
listen = /var/run/php5-fpm.sock
listen.group = www-data
listen.mode = 0660
pm = dynamic
pm.max_children = 100
pm.start_servers = 40
pm.min_spare_servers = 40
pm.max_spare_servers = 100
pm.max_requests = 10000
I've already confirmed that it's not an issue with the database - I saw the exact same behaviour after doubling the number of MySQL read slaves.
What is causing this? How can I stop it?
EDIT:
Here is a graph that demonstrates what I'm seeing. Note that the failure rate usually spikes just as the user_count peaks, and gradually settles back down.