The setup
We have a Debian Linux set up with MySQL v5.1.73 (innoDB storage engine) and puppet-dashboard version 1.2.23. As you probably guessed, puppet-dashboard is using MySQL as its backend.
Also, it shouldn't be relevant but this a VMware virtual machine on vSphere 5.5.
The problem
The problem is that, despite the number of puppet nodes and run frequency staying relatively the same, the disk space used by MySQL keeps on increasing in a disturbing fashion to the point where it is now becoming an issue.
The following graph illustrates the issue.
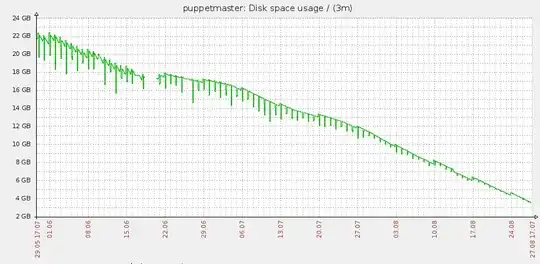
We have put in place the two cron jobs that should allow disk space to be freed. They are the following and both run daily :
- rake RAILS_ENV=production db:raw:optimize
- rake RAILS_ENV=production reports:prune:orphaned upto=3 unit=mon
The drops you can see in the graph are the cron jobs running and eating up more space trying to free some space.
MySQL binary logs are not enabled. 95% of the disk space used on this server is located in the /var/lib/mysql/dashboard_production which is the directory where the MySQL data is stored.
We have had this issue before with a different application (Zabbix monitoring) and had to dump the DB and re-import in order to free up space. This was a very painful process and not a very elegant solution but it ultimately worked.
Is there any way we can reclaim this disk space ? What we can do this stop this behavior ?
Edit 1
We are indeed using innoDB and we are not using configuration directive "innodb_file_per_table".
As requested by Felix, the output of the command is the following :
+----------------------+-------------------+-------------+
| table_schema | table_name | data_length |
+----------------------+-------------------+-------------+
| dashboard_production | resource_statuses | 39730544640 |
| dashboard_production | metrics | 643825664 |
| dashboard_production | report_logs | 448675840 |
| dashboard_production | timeline_events | 65634304 |
| dashboard_production | reports | 50937856 |
| dashboard_production | resource_events | 38338560 |
| glpidb | glpi_crontasklogs | 21204608 |
| ocsweb | softwares | 8912896 |
| ocsweb | deploy | 5044208 |
| phpipam | logs | 1269584 |
+----------------------+-------------------+-------------+
Also, I will be trying the reports:prune task without the "orphaned" option as mentionned as well as the other alternatives and will keep this question updated.
Edit 2
I ran the reports:prune rake task and, despite deleting 230000 reports, it kept on eating more space... I will therefore move on to the other options.
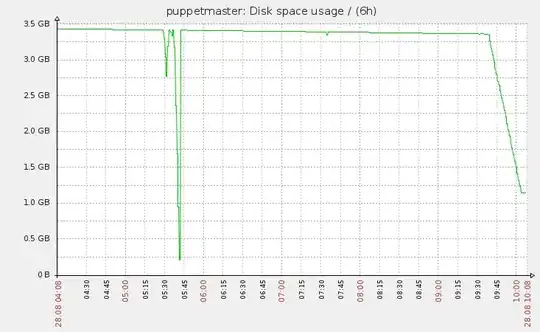
The solution
After deleting two thirds of the entries in the database, it only freed up 200MB of disk space which is senseless. We ended up dumping the content and re-importing it taking care to enable "innodb_file_per_table".
We will just have to wait and see if this fixes the solution in the long term but it seems to be the case for the moment.