I'm having an nginx running on debian. Nginx will reload every 2 minutes to fetch newly created vhosts. After a while new vhosts weren't loading anymore, but old vhosts kept on being served by nginx
In my nginx error log, I can find multiple errors.
2014/08/10 06:30:05 [alert] 27891#0: epoll_ctl(1, 4) failed (9: Bad file descriptor)
2014/08/10 06:30:05 [alert] 27892#0: close() channel failed (9: Bad file descriptor)
2014/08/10 06:30:05 [alert] 27893#0: close() channel failed (9: Bad file descriptor)
2014/08/10 06:30:19 [alert] 4806#0: worker process 27891 exited with fatal code 2 and can not be respawn
2014/08/10 06:30:19 [alert] 4806#0: sendmsg() failed (9: Bad file descriptor)
2014/08/10 06:30:05 [alert] 27894#0: close() channel failed (9: Bad file descriptor)
2014/08/10 06:30:20 [alert] 4806#0: sendmsg() failed (9: Bad file descriptor)
2014/08/10 06:30:20 [alert] 4806#0: sendmsg() failed (9: Bad file descriptor)
2014/08/10 06:30:20 [alert] 4806#0: sendmsg() failed (9: Bad file descriptor)
2014/08/10 06:30:20 [alert] 4806#0: sendmsg() failed (9: Bad file descriptor)
I've tried to find a solution in the past and ended up adding
worker_rlimit_nofile 300000;
But looks like that didn't do the trick.
I have the feeling that my box runs out of memory at some point, but not entirely sure.
Restarting nginx fixed the problem, but I fear I might run into this again after a while.
Another weird thing what I've seen is, after restarting nginx the swap just dissapeared in my stats. (see screenshots).
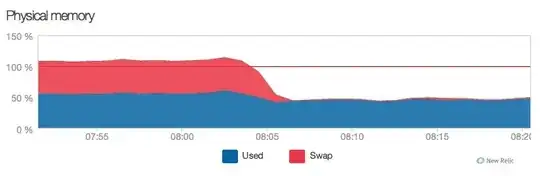
In case you want to see my nginx.conf, here it is:
user www-data;
worker_processes 4;
worker_rlimit_nofile 300000;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
events {
worker_connections 2000;
# multi_accept on;
}
http {
include /etc/nginx/mime.types;
server_names_hash_max_size 812000;
geoip_country /etc/nginx/geoip/GeoIP.dat; # the country IP database
geoip_city /etc/nginx/geoip/GeoLiteCity.dat; # the city IP database
log_format withhost '$host - $remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';
# access_log /var/log/nginx/access.log withhost;
# set_real_ip_from 141.101.64.0/18;
# set_real_ip_from 108.162.192.0/18;
# set_real_ip_from 190.93.240.0/20;
# set_real_ip_from 2400:cb00::/32;
# set_real_ip_from 2606:4700::/32;
set_real_ip_from 69.164.223.55;
set_real_ip_from 212.123.14.6;
set_real_ip_from 192.168.255.17;
real_ip_header X-Forwarded-For;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
tcp_nodelay on;
server_tokens off;
gzip on;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
include /etc/nginx/conf.d/*.conf;
include /nfs/vhosts/*;
include /etc/nginx/sites-enabled/*;
}
Hope someone can help me identify the cause of this problem and help me fix it.
Regards!