Yesterday the CPU on my Xen-based VPS server went to 100% for two hours and then went back to normal, seemingly naturally.
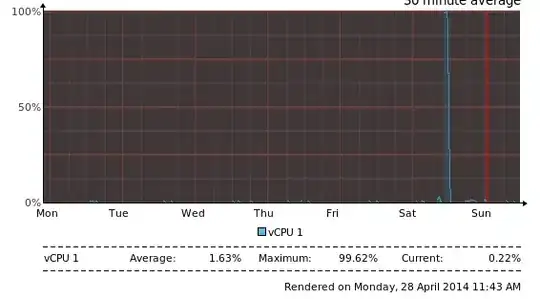
I have checked logs including syslog, auth.log and more and nothing seems out of the ordinary.
- During this time, the server seemed to be operating as normal as indicated by people logging in, emails received etc
- Memory, disk and network usage during this time appeared to be normal.
- I hadn't rebooted the server in weeks, and I wasn't working on it that morning.
- I keep it updated with security updates and the like. It's 12.04 LTS.
- It runs nginx, mysql and postfix along with a few other things.
Around the start of the event syslog contains these entries:
Apr 27 07:55:34 ace kernel: [3791215.833595] [UFW LIMIT BLOCK] IN=eth0 OUT= MAC=___ SRC=209.126.230.73
DST=___ LEN=40 TOS=0x00 PREC=0x00 TTL=244 ID=2962 PROTO=TCP SPT=49299 DPT=465 WINDOW=1024 RES=0x00 SYN URGP=0
Apr 27 07:55:34 ace dovecot: pop3-login: Disconnected (no auth attempts): rip=209.126.230.73, lip=___
Apr 27 07:55:34 ace kernel: [3791216.012828] [UFW LIMIT BLOCK] IN=eth0 OUT= MAC=___ SRC=209.126.230.73
DST=___ LEN=40 TOS=0x00 PREC=0x00 TTL=244 ID=58312 PROTO=TCP SPT=49299 DPT=25 WINDOW=1024 RES=0x00 SYN URGP=0
Apr 27 07:55:34 ace kernel: [3791216.133155] [UFW LIMIT BLOCK] IN=eth0 OUT= MAC=___ SRC=209.126.230.73
DST=___ LEN=76 TOS=0x00 PREC=0x00 TTL=244 ID=63315 PROTO=UDP SPT=49299 DPT=123 LEN=56
But then again, I get these all the time. It just indicates UFW/iptables successfully blocked some unwanted connections. It shouldn't be related.
I have a daily backup that runs just under 2 hours prior to the start of this "event". It seemed to run normally although it did cause a higher server load (but not CPU utilisation) than normal, pointing to a possible I/O congestion issue. But it didn't coincide with the 100% CPU event.
My question is: how can I investigate the cause of an event like this that happened in the past, given that it's no longer happening?