Travis, "archive" did not help you. In fact, even clearing the event log when it was 2/3rd grown did not help you. But "archive" did help KraigM.
kce: cleared a 131MB "overwrite" file and saw performance drop from say 55% o 5% but QUESTION: perhaps you eventually you saw high utilization again since this may (a) only be triggered when the overwriting condition is reached or (b) it may get linearly worse as the cleared file increases from 0mb in size to 131MB in size.
Some see this for the security.evtx and one saw it for the Task Scheduler operational log. I suggest completely uninstalling your AV (which one are you using) and trying. Intruders need to hide their tracks and their tracks are made in scheduled tasks they set up or logins they do. So they will hide their tracks by breaking handles to these event logs and rewriting them to skip over their tracks. AVs may may be detecting this in a buggy Way since if it were Microsoft, more of this high utilization would have been reported but I am seeing just a scant few posts when Googling. I am also seeing this on server 2008 R2 for the security.evtx log. No event log subscribers, no external monitors. I observed a couple of AV services (McAfee) running and they had very low total utilization for a server up so many days so I suspect it was uninstalled and only partially so (likely needs McAfee's special uninstaller) and I wonder if there are hooks in the vestige (or even normally installed) McAfee service or McAfee filter drivers running that somehow take a normal write to the event log and decide in their filtering that they need to turn this into a full blown read of the entire event log. Trust me, third party filter drivers from some AV companies are buggy and certainly 10000x buggier than Microsoft's implementation of event logging, which is very likely perfect. In summary, 100% uninstall ALL OF YOUR av AND SEE IF issue resolves. If so, work with your AV company to fix their AV. It's ill-advised to make file exceptions for .EVTX files since you may be losing out on this intrusion detection, which believe me, is important to bad guys.
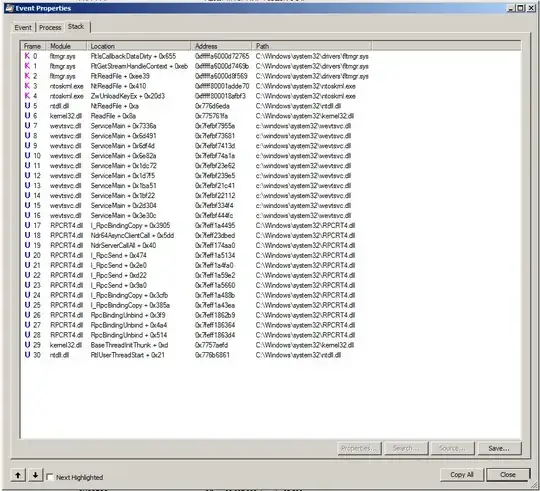
Also, when using procmon, pay attention to WriteFile calls because the Writefile is what will trigger the filter manager to read the entire file. In my case, the read was initiated approximately 30-seconds after the write completed which might be by design. But it was consistent and in my case the file was 4GB and the file read involved 64K Readfiles each 64KB in length and it utilized 35% of the CPU to accomplish this. Very sad.
Update 03/23/2016
I looked at the filter drivers on this machine after concluding this had to be caused by one of them (the event log mechanism could never be buggy on it's own or the number of reports of this kind would be staggering and it is not). I saw some filter drivers from an AV and from a well known 3rd party company which boosts virtual machine disk performance with look ahead reads and asked their chief architect (who was very kind and gracious) if his product might be over-aggressively reading the entire security event log (which was clearly happening per procmon). This would be helpful for smaller security logs but not the ones of the sizes reported here. No way he said. He agreed it might be the AV.
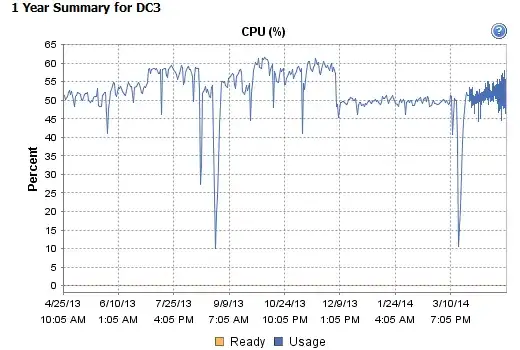
As I said to the Azure fellow below, we do not have a followup from the original Poster if the problem re-surfaced after clearing the event log because that is a common and mistaken solution since the performance degrades over time yet again. This is called "followup" and I see first-hand the original poster's solution can fool those who don't followup into believing they have solved the problem. I almost got fooled as well. I cleared the event log and performance improved -- but I used procmon and saw the issue will grow and grow slowly over time until it becomes problematic. For some reason, the Azure fellow harshly criticizes me when the original poster didn't followup (may have died, been fired, quit, or gotten busy). The Azure fellow below thinks if the original poster didn't followup, it must be a fixed problem. This is vexing and puzzling because I can't think of anyone who is so highly regarded technically who would take this position. I apologize if I pricked a nerve. Perhaps in my activism elsewhere on the Internet where I call people out I got on his nerve -- here (serverfault) I am simply being kind and sharing deep technical knowledge and the result from Mr. Azure is bullying about whether my technical contribution is even necessary or is for some blog of mine (I have no such blog). I don't yet intend to send this link to around half a dozen key cronies at Microsoft and ask them what the hey is going on with this type of bullying from a key MSFT employee because I am singularly focused on having the best of interest of the community in mind and the responses below from Mr. Azure are, in a few words, unbelievable, vitriolic, unnerving and bullying -- which I am sure some people enjoy doing to others. I was initially offended but am over it and know that, passive or active readers will appreciate what I am saying and appreciate my comments -- I stand 100% behind it without regard for legalistic reasons why it is subtly inappropriate here or not. M. Azure, please practice kindness and refrain from casting my comments in a poor light. Just get over it and show restraint and not comment yet again.
Harry