I have a brand new CentOS 6.5 install with two (mounted to /mnt/data) 1tb Western Digital Black drives in raid 1 with mdadm, configured via the installer. Unfortunately every now and again the entire system kernel panics with a trace similar to below:
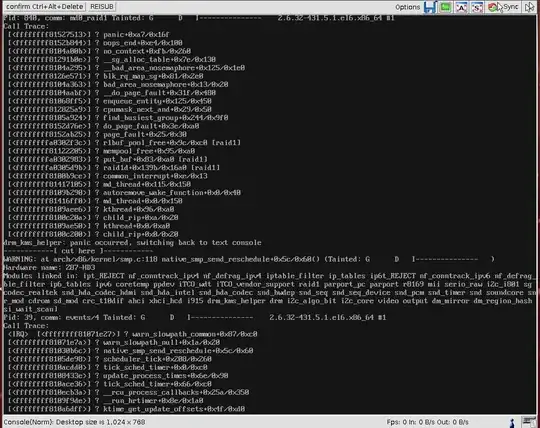
Any tips on diagnosing or fixing this? Much appreciated!
EDIT: It appears this happened around the same time as a raid data check occured: EDIT 2: The last two crashes have happened at just past 1am Sunday, same time data check occurs.
Mar 23 01:00:02 beta kernel: md: data-check of RAID array md0
Mar 23 01:00:02 beta kernel: md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
Mar 23 01:00:02 beta kernel: md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for data-check.
Mar 23 01:00:02 beta kernel: md: using 128k window, over a total of 976629568k.
/proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc1[1] sdb1[0]
976629568 blocks super 1.1 [2/2] [UU]
bitmap: 0/8 pages [0KB], 65536KB chunk
unused devices: <none>
mdadm -D
/dev/md0:
Version : 1.1
Creation Time : Fri Mar 7 16:07:17 2014
Raid Level : raid1
Array Size : 976629568 (931.39 GiB 1000.07 GB)
Used Dev Size : 976629568 (931.39 GiB 1000.07 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Sun Mar 23 03:36:59 2014
State : active
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Name : beta.fmt2.spigot-servers.net:0 (local to host beta.fmt2.spigot-servers.net)
UUID : 89a86538:f6162473:d5e0524c:b80566d6
Events : 1728
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
EDIT 3: Different crash, occurred during a forced resync / check, also memtest passed 4 passes just fine: http://files.md-5.net/s/X3Hi.png
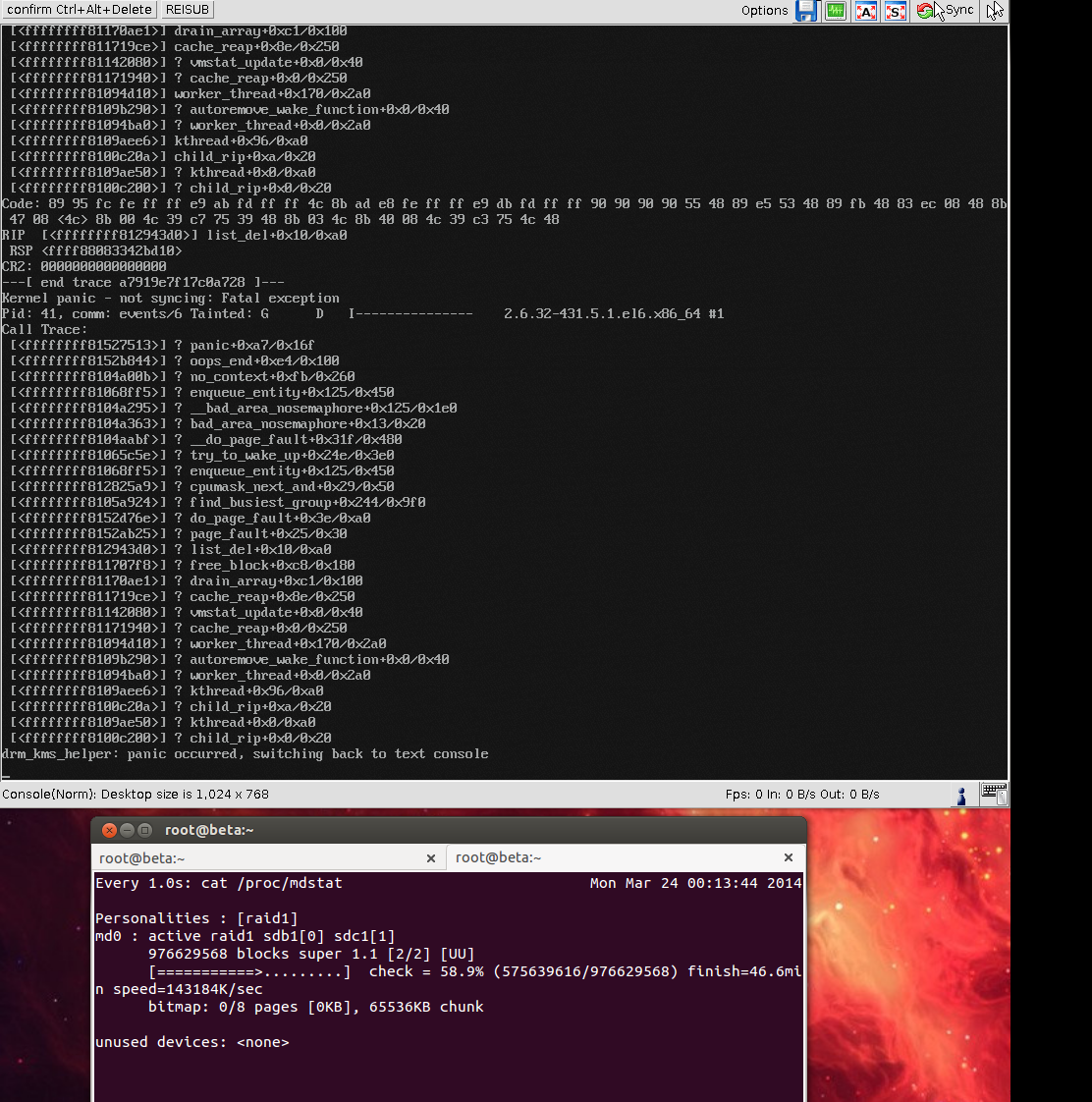{kind=link}
EDIT 4: Even dd is causing crashes: http://files.md-5.net/s/hba2.png
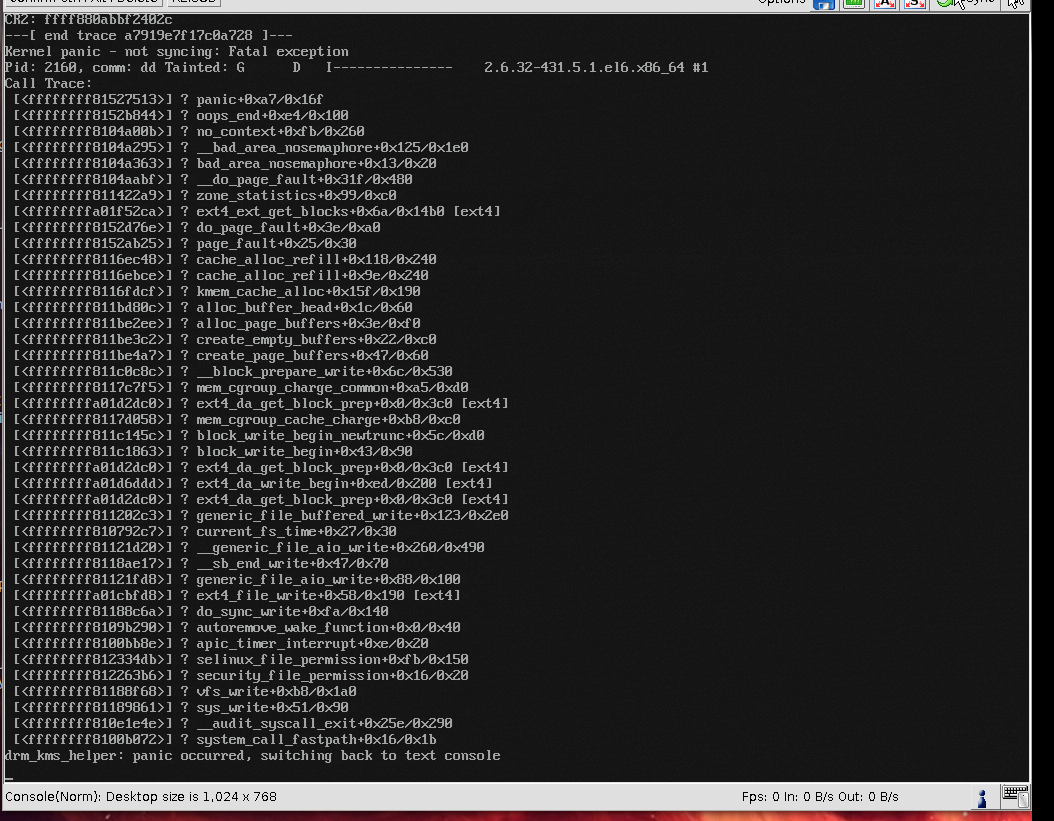{kind=link}
EDIT 5: The SSD survives the dd torture test, guess that means I'm gonna try the drives without raid.