We have a couple dozen Proxmox servers (Proxmox runs on Debian), and about once a month, one of them will have a kernel panic and lock up. The worst part about these lock ups is that when it's a server that is on a separate switch than the cluster master, all other Proxmox servers on that switch will stop responding until we can find the server that has actually crashed and reboot it.
When we reported this issue on the Proxmox forum, we were advised to upgrade to Proxmox 3.1 and we've been in the process of doing that for the past several months. Unfortunately, one of the servers that we migrated to Proxmox 3.1 locked up with a kernel panic on Friday, and again all Proxmox servers that were on that same switch were unreachable over the network until we could locate the crashed server and reboot it.
Well, almost all Proxmox servers on the switch... I found it interesting that the Proxmox servers on that same switch that were still on Proxmox version 1.9 were unaffected.
Here is a screen shot of the console of the crashed server:
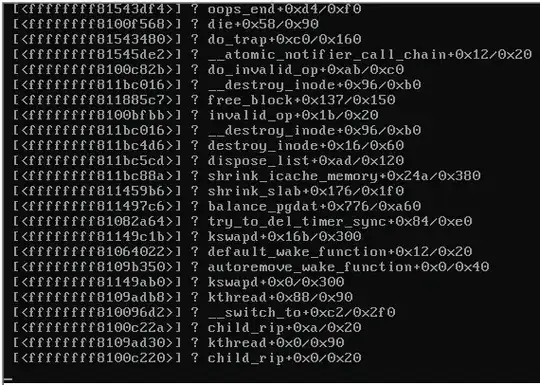
When the server locked up, the rest of the servers on the same switch that were also running Proxmox 3.1 became unreachable and were spewing the following:
e1000e 0000:00:19.0: eth0: Reset adapter unexpectedly
e1000e 0000:00:19.0: eth0: Reset adapter unexpectedly
e1000e 0000:00:19.0: eth0: Reset adapter unexpectedly
...etc...
uname -a output of locked server:
Linux ------ 2.6.32-23-pve #1 SMP Tue Aug 6 07:04:06 CEST 2013 x86_64 GNU/Linux
pveversion -v output (abbreviated):
proxmox-ve-2.6.32: 3.1-109 (running kernel: 2.6.32-23-pve)
pve-manager: 3.1-3 (running version: 3.1-3/dc0e9b0e)
pve-kernel-2.6.32-23-pve: 2.6.32-109
Two questions:
Any clues what would be causing the kernel panic (see image above)?
Why would other servers on the same switch and version of Proxmox be knocked off the network until the locked server is rebooted? (Note: There were other servers on the same switch that were running the older 1.9 version of Proxmox that were unaffected. Also, no other Proxmox servers in the same 3.1 cluster were affected that were not on that same switch.)
Thanks in advance for any advice.