I have been using Microsoft’s Hyper-V technology for a little while now, but I am just now dipping my toe into clustering.
In particular, I am trying to implement a fault-tolerant SQL DB. This involves setting up two VMs, clustering them via Failover Cluster, and then installing SQL Server in some fashion. I have two physical machines - one high-end and rather beefy “heavy lifter” to contain the majority of the VMs, and another “backup” (a repurposed desktop) to hold the essential “secondary” (or failover) AD-DC, SQL and FS VMs.
The main reason why I find the failover cluster at the VM level so attractive is that it presents a single IP and DNS entry to the network as a whole - if one machine (physical or virtual) goes down, you might loose some ping and the connections get reset, but the network applications (Microsoft RMS connection to backend SQL) can still connect to a viable DB without having to mess around with the settings at all.
My first question is in terms of SQL Server itself. If I have a cluster between two VMs, does it make more sense to install the SQL Server in Failover Cluster configuration or should I simply install it in a stand-alone config and mirror the DBs? For example, this post suggests just mirroring the DBs, but do I just mirror standalone DBs on standalone VMs, or can I get the network and failover benefits of clustered VMs while still utilizing (on each clustered VM) standalone DBs that have been mirrored between each other?
As well, I have come across a lot of documentation about SQL clustering, but most assume a number (#>2) of physical machines to hold not only the actual SQL VMs but also the Quorum and Witness stores. I will not be able to muster more than two physical machines. As such, I will have to be satisfied with a VM cluster that does not exceed two VMs (one for each physical machine).
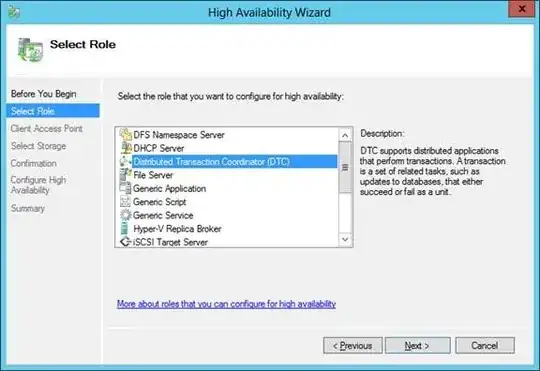
Another issue involves MSDTC - the Distributed Transaction Coordinator. When attempting to install the SQL Failover Cluster (I never completed it for this reason) it threw a hissy fit because MSDTC had not been clustered. Search as I might, I have not yet found a way to do so under Windows Server 2012 R2. I have found plenty of docs for Windows 2008 and 2008 R2, but these instructions don’t align with 2012 R2 (at least, not in a way that allows me to successfully cluster MSDTC). Plus, some of the instructions that I have found for SQL Server Failover Cluster installation suggest that a third “network device” - shared network storage (a SAN) - is required for the DB itself (and other functionality). I do not have this, and won’t be getting this. Most of my storage exists on the “heavy lifter” that was designed for all of the “primary” VMs. If that physical machine goes down, so does the storage. The secondary server does have enough resources for an AD-DC Server, an SQL server and a File Server, so it will handle the “secondary” failover versions of those VMs (clustered or not).
My final question involves file servers. If I cluster file servers between two VMs (one on my “heavy lifter” and another on my “backup”, how do I mirror the data between them? Clustering VMs only provides a single point of access on the network for a resource, it doesn’t exactly replicate data between the two - that is left to the services that serve up that data. I am unsure how I can ensure that file server data between two clustered file server VMs can be properly mirrored. Remember, I only have two devices to be used here - my primary machine and a backup secondary. There is no chance of me obtaining a SAN or any other type of network attached storage. What exists on the machines must act as the storage.
Thanks in advance for any suggestions.