Here's what I have done so far:
Using more Rx/Tx buffers boosts performance the most from defaults. I set RSS Queues to 4 on each adapter, and specified starting RSS CPU on the second port to something other than 0 (it's 16 on the PC that I use, with 16 cores, 32 HTs).
From watching ProcessExplorer, I am limited by CPU's ability to handle the large number of incoming interrupts, even with RSS enabled. I am using PCIe x8 (electrical) slot in 2.x mode. Each of the two adapters connects with a 5GT/sec x8 bus.
OS responsiveness does not matter, I/O throughput does. I am limited by clients' inability to process Jumbo packets.
What settings should I try next?
Details: Dual Xeon-E5 2665, 32 GB RAM, eight SSDs in RAID0 (RAMDrive used for NIC perf validation), 1TB data to be moved via IIS/FTP from 400 clients, ASAP.
In response to comments:
Actual read throughput is 650 MB/sec over a teamed pair of 10Gb/sec links, into RAM Drive
Antivirus and firewall are off, AFAICT. (I have fairly good control over what's installed on the PC, in this case. How can I be sure that no filters are reducing performance? I will have to follow up, good point.)
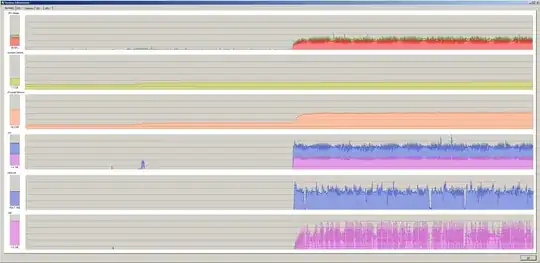
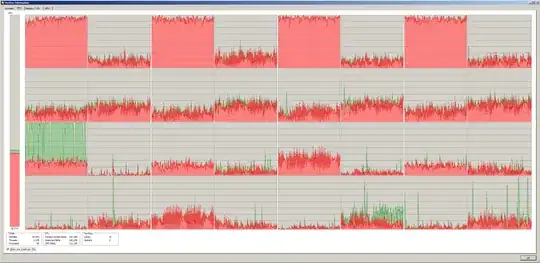
In Process Explorer, I see spells of time where CPU keeps going (red, kernel time), but network and disk I/O are stopped
Max RSS processors is at its default value, 16
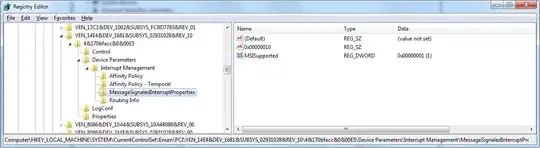
Message-signaled intrrupts are supported on both instances of X520-DA2 device, with MessageNumberLimit set to 18. Here's what I see on my lowly desktop card