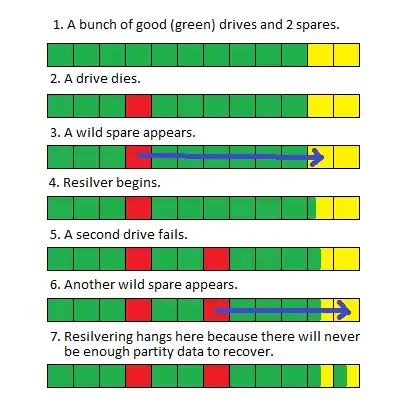
I have a large (> 100TB) ZFS (FUSE) pool on Debian that lost two drives. As the drives failed, I replaced them with spares until I could schedule an outage and physically replace the bad disks.
When I took the system down and replaced the drives, the pool started resilvering as expected, but when it gets to about 80% complete (this usually takes about 100 hours) it restarts again.
I'm not sure if replacing two drives at once created a race condition, or if due to the size of the pool the resilver takes so long that other system processes are interrupting it and causing it to restart, but there's no obvious indication in the results of 'zpool status' or the system logs that point to a problem.
I have since modified how I lay out these pools to improve resilvering performance but any leads or advice on getting this system back into production are appreciated.
zpool status output (the errors are new since last time I checked):
pool: pod
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://www.sun.com/msg/ZFS-8000-8A
scrub: resilver in progress for 85h47m, 62.41% done, 51h40m to go
config:
NAME STATE READ WRITE CKSUM
pod ONLINE 0 0 2.79K
raidz1-0 ONLINE 0 0 5.59K
disk/by-id/wwn-0x5000c5003f216f9a ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CWPK ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQAM ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BPVD ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQ2Y ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CVA3 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQHC ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BPWW ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09X3Z ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQ87 ONLINE 0 0 0
spare-10 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-1CH_W1F20T1K ONLINE 0 0 0 1.45T resilvered
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09BJN ONLINE 0 0 0 1.45T resilvered
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQG7 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQKM ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQEH ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09C7Y ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CWRF ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQ7Y ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0C7LN ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQAD ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CBRC ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BPZM ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BPT9 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQ0M ONLINE 0 0 0
spare-23 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-1CH_W1F226B4 ONLINE 0 0 0 1.45T resilvered
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CCMV ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0D6NL ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CWA1 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CVL6 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0D6TT ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BPVX ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09BGJ ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0C9YA ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09B50 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0AZ20 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BKJW ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F095Y2 ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F08YLD ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQGQ ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0B2YJ ONLINE 0 0 39 512 resilvered
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQBY ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0C9WZ ONLINE 0 0 0 67.3M resilvered
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQGE ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0BQ5C ONLINE 0 0 0
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CWWH ONLINE 0 0 0
spares
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F0CCMV INUSE currently in use
disk/by-id/scsi-SATA_ST3000DM001-9YN_Z1F09BJN INUSE currently in use
errors: 572 data errors, use '-v' for a list