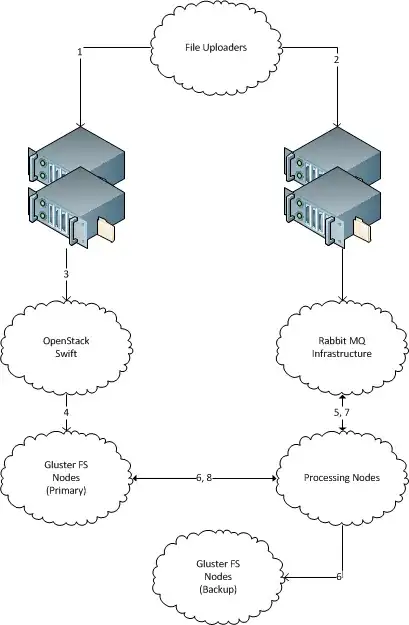
A bunch of new files with unique filenames regularly "appears"1 on one server. (Like hundreds GBs of new data daily, solution should be scalable to terabytes. Each file is several megabytes large, up to several tens of megabytes.)
There are several machines that process those files. (Tens, should solution be scalable to hundreds.) It should be possible to easily add and remove new machines.
There are backup file storage servers on which each incoming file must be copied for archival storage. The data must not be lost, all incoming files must end up delivered on the backup storage server.
Each incoming file myst be delivered to a single machine for processing, and should be copied to the backup storage server.
The receiver server does not need to store files after it sent them on their way.
Please advise a robust solution to distribute the files in the manner, described above. Solution must not be based on Java. Unix-way solutions are preferable.
Servers are Ubuntu-based, are located in the same data-center. All other things can be adapted for the solution requirements.
1Note that I'm intentionally omitting information about the way files are transported to the filesystem. The reason is that the files are being sent by third parties by several different legacy means nowadays (strangely enough, via scp, and via ØMQ). It seems easier to cut the cross-cluster interface at the the filesystem level, but if one or another solution actually will require some specific transport — legacy transports can be upgraded to that one.