As far as I know, no.
'zpool copies' creates redundant bits as you know, and as I recall, it is supposed to try to push those redundant bits as far away geographically as possible, but I don't believe it is a hard & fast requirement like it is for mirrored bits in a mirror vdev; space constraints, other moving pieces could I believe lead to a scenario where copy #2 is still on the same disk. If that happens even once, then losing a drive from such a config would be a problem, data retention wise.
Nor is it something that the pool administrative commands are designed to treat in the same way they'd treat mirrored vdevs. Nor is it something the ZFS workflow is designed to treat the same way it does mirrored or parity vdevs -- if you lost a disk out of a pool that had multiple disks as top-level vdevs, even if you had copies=2 or higher set right from day 1, I would expect ZFS to complain mightily, and possibly begin returning errors for data access.
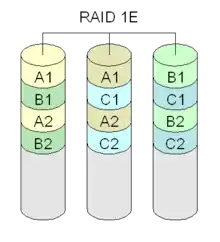
I would not expect copies=2 (or more) to act like RAID 1E. However, if you created multiple partitions on your disks, and set them up in the proper mirrored vdevs, you could probably replicate the idea of RAID 1E with ZFS. If you had 3 drives, each with 2 partitions, and you set up the mirror vdevs so that each pair of partitions are not from the same drive, then the resulting pool could survive a single disk loss. The performance characteristics of such a pool, however, have never been explored to my knowledge (I'd surmise they would be bad).