Caveat: there may be inaccuracies below. I've been learning about a lot of this stuff as I go along, so take it with a pinch of salt. This is quite long, but you could just read the parameters we were playing with, then skip to the Conclusion at the end.
There are a number of layers where you can worry about SQLite write performance:

We looked at the ones highlighted in bold. The particular parameters were
- Disk write cache. Modern disks have RAM cache which is used to optimise disk writes with respect to the spinning disk. With this enabled, data can be written in out-of-order blocks, so if a crash happens, you can end up with a partially written file. Check the setting with hdparm -W /dev/... and set it with hdparm -W1 /dev/... (to turn it on, and -W0 to turn it off).
- barrier=(0|1). Lots of comments online saying "if you run with barrier=0, then don't have disk write caching enabled". You can find a discussion of barriers at http://lwn.net/Articles/283161/
- data=(journal | ordered | writeback). Look at http://www.linuxtopia.org/HowToGuides/ext3JournalingFilesystem.html for a description of these options.
- commit=N. Tells ext3 to sync all data and metadata every N seconds (default 5).
- SQLite pragma synchronous=ON | OFF. When ON, SQLite will ensure that a transaction is "written to disk" before continuing. Turning this off essentially makes the other settings largely irrelevant.
- SQLite pragma cache_size. Controls how much memory SQLite will use for it's in-memory cache. I tried two sizes: one where the whole DB would fit in cache, and one where the cache was half of max DB size.
Read more about the ext3 options in the ext3 documentation.
I ran performance tests on a number of combinations of these parameters. The ID is a scenario number, referred to below.
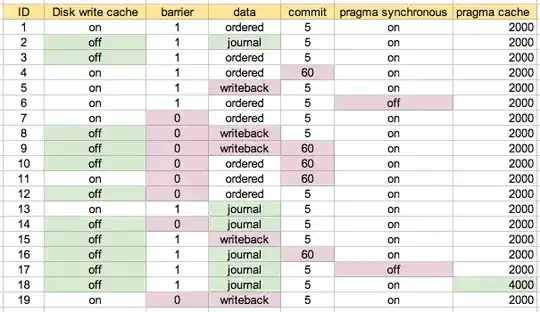
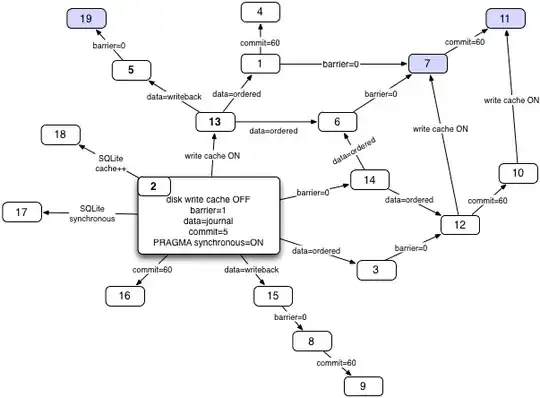
I started off by running with the default configuration on my machine as scenario 1. Scenario 2 is what I assume to be the "safest", and then tried various combinations, where appropriate / prompted. This is probably easiest to understand with the map I ended up using:
I wrote a test script which ran a lot of transactions, with inserts, updates, and deletes, all on tables with either INTEGER only, TEXT only (with id column), or mixed. I ran this a number of times on each of the configurations above:
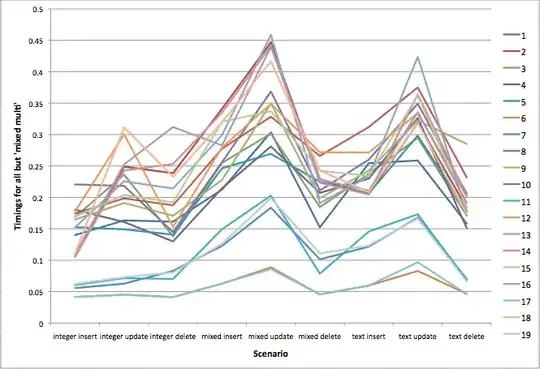
The bottom two scenarios are #6 and #17, which have "pragma synchronous=off", so unsurprising that they were the fastest. The next cluster of three are #7, #11, and #19. These three are highlighted in blue on the "configuration map" above. Basically the configuration is disk write cache on, barrier=0, and data set to something other than 'journal'. Changing commit between 5 seconds (#7) and 60 seconds (#11) seems to make little difference. On these tests there didn't seem to be much if any difference between data=ordered and data=writeback, which surprised me.
The mixed update test is the middle peak. There is a cluster of scenarios that are more clearly slower on this test. These are all ones with data=journal. Otherwise there's not much between the other scenarios.
I had another timing test, which did a more heterogenous mix of inserts, updates and deletes on the different type combinations. These took a lot longer, which is why I didn't include it on the above plot:
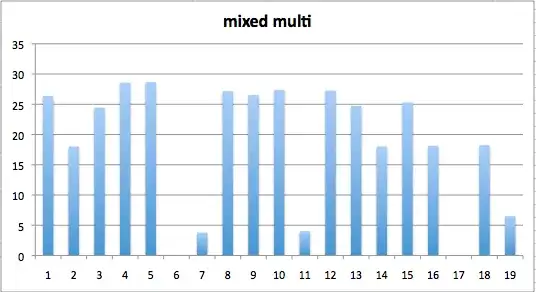
Here you can see that the writeback configuration (#19) is a bit slower than the ordered ones (#7 and #11). I expected writeback to be slightly faster, but perhaps it depends on your write patterns, or maybe I just haven't read enough on ext3 yet :-)
The various scenarios were somewhat representative of the operations done by our application. After picking a shortlist of scenarios we ran timing tests with some of our automated test suites. They were in line with the results above.
Conclusion
- The commit parameter seemed to make little difference, so we're leaving that at 5s.
- We're going with disk write cache on, barrier=0, and data=ordered. I read some things online that thought this is a bad setup, and others which seemed to think this should be the default in a lot of situations. I guess most important is that you make an informed decision, knowing what trade-offs you're making.
- We're not going to using the synchronous pragma in SQLite.
- Setting the SQLite cache_size pragma so the DB would fit in memory improved performance on some operations, as we expected.
- The above configuration means we're taking slightly more risk. We'll be using the SQLite backup API to minimise the danger of disk failure on a partial write: taking a snapshot every N minutes, and keeping the last M around. I tested this API while running performance tests, and it's given us confidence to go this way.
- If we still wanted more, we could look at mucking about with the kernel, but we improved things enough without going there.
Thanks to @Huygens for various tips and pointers.