I've been reading a lot about high availability virtualization, either via Hyper-V or VMWare. In that context, essentially high availability means that the VM is hosted by a cluster of physical servers (nodes), so if one of the physical servers goes down, the VM can still be served by other physical servers. So far so good, the physical cluster and the VM itself are highly available.
However if the service being provided, let's say SQL server, MSDTC, or any other service, are actually being provided by the VM image and the virtualized operating system. So I imagine that there is still a point of failure at the virtual layer that isn't accounted for. Something could happen within the virtual machine itself that the physical cluster can not account for, correct? In that instance the physical failover cluster (Hyper-V) or VMWare host, can not fail over, because the issue is not with one of the servers in the physical cluster - failing over a physical node would not do any good.
Does this necessitate building a virtual failover cluster on top of the physical one, or is this not necessary?
Alternatively, I suppose you could skip the phsyical clustering, and just cluster at the virtual layer (Child based failover clustering), because that should still survive a physical failure.
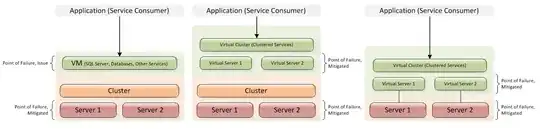
See image below showing parent based (left), child based (right) and a combination (center). Is parent based as far as you need to go, or is child based more appropriate?