This is probably a continuation of my previous (unanswered) question because the underlying cause is probably the same.
I have a Linux server with nginx and sshd running on it. It's on a shared 100mbit/s unmetered link. During "peak times" (basically, during the day in the US), sftp performance becomes very bad, sometimes timing out before I can even connect. ssh is unaffected. I know it's nginx because when I stop nginx, the problem with sftp goes away instantly. However, nginx itself has essentially zero latency during these "episodes."
This is a long-standing problem with my server, and I set out recently to take care of it once and for all. Yesterday I began to suspect that the sheer volume of http traffic coupled with the greater latency induced by a lack of upstream bandwidth was crowding out my sftp traffic. I used tc to add some prioritization:
/sbin/tc qdisc add dev eth1 root handle 1: prio
/sbin/tc filter add dev eth1 protocol ip parent 1: prio 1 u32 match ip dport 22 0xffff flowid 1:1
/sbin/tc filter add dev eth1 protocol ip parent 1: prio 1 u32 match ip sport 22 0xffff flowid 1:1
/sbin/tc filter add dev eth1 protocol ip parent 1: prio 1 u32 match ip protocol 1 0xff flowid 1:1
Unfortunately, even though I can see sftp packets accumulating in the first prio:
class prio 1:1 parent 1:
Sent 257065020 bytes 3548504 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
class prio 1:2 parent 1:
Sent 291943287326 bytes 206538185 pkt (dropped 615, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
class prio 1:3 parent 1:
Sent 22399809673 bytes 15525292 pkt (dropped 2334, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
... latency is still unacceptable when connecting. Here are some pretty graphs I made just now while trying to correlate something with the sftp latency:
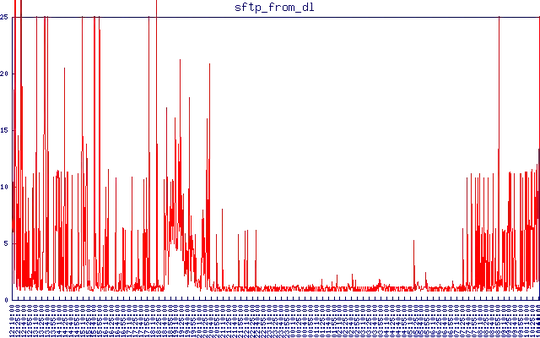 Here is sftp latency from a different location. I have the timeout set at 25 seconds. Anything greater than the normal 1-2 seconds it takes to connect and download a tiny file is unacceptable to me. You can see how it becomes OK during the night and then latency kicks in again during the day.
Here is sftp latency from a different location. I have the timeout set at 25 seconds. Anything greater than the normal 1-2 seconds it takes to connect and download a tiny file is unacceptable to me. You can see how it becomes OK during the night and then latency kicks in again during the day.
 Content of
Content of /proc/net/sockstat. Note the apparent correlation of sftp latency with tcp memory use. No idea what that might mean.
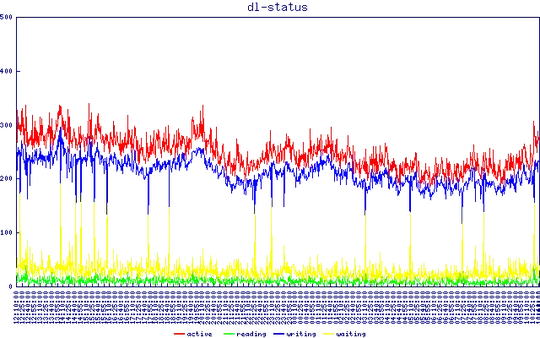 Output of nginx's stub-status module. Nothing to see here ...
Output of nginx's stub-status module. Nothing to see here ...
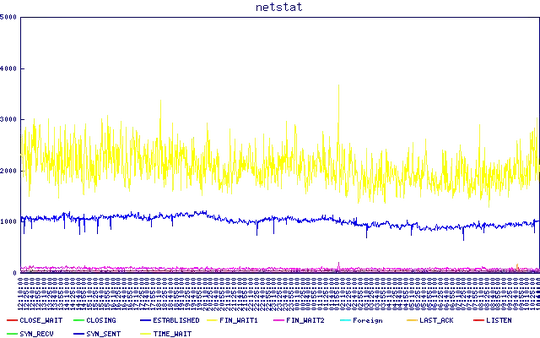 Output of
Output of netstat -tan | awk '{print $6}' | sort | uniq -c. Again, seems flat.
So why isn't tc working for me? Do I need to actually limit bandwidth rather than just prioritizing port 22 in and out? Or is tc the wrong tool for the job and I'm totally missing the real cause of the bad sftp performance?
Output of uname -a:
Linux [redacted] 3.2.0-0.bpo.2-amd64 #1 SMP Fri Jun 29 20:42:29 UTC 2012 x86_64 GNU/Linux
I'm running nginx 1.2.2 with the mp4 streaming module compiled in.
Edit 2012/07/31:
ewwhite asked whether I'm near or at my bandwidth limit. I checked, and there does seem to be a correlation (though not a perfect one) between the 100 mbit limit and the bad sftp latency:


Why, though, would sftp traffic (associated with port 22) not be prioritized higher than http traffic during these episodes?
Edit 2012/07/31 #2
In collecting sftp/scp latency data, I noticed a pattern, as shown in the below graph (the green lines I added):

Two clusters - subtracting "baseline" latency, they are at ~5 and ~10 seconds. You can also see them pretty clearly on the above sftp latency graph on a much larger timescale. Where is this 5 second number coming from?