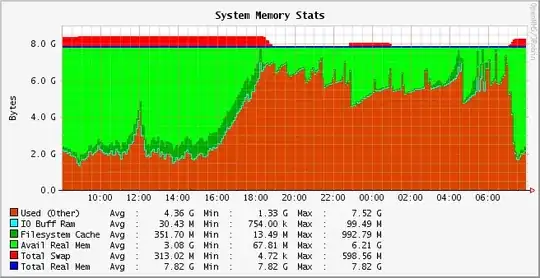
An Apache webserver running a mod_perl application is exposing abnormal memory usage - after the "day load" ceases, the system's memory is being exhausted by the Apache processes and oom_killer is being invoked. As the load returns the following morning, the memory usage normalizes - probably because Apache workers get recycled periodically if a sufficient number of hits is generated:
This is the graph for apache hits per second to correlate:
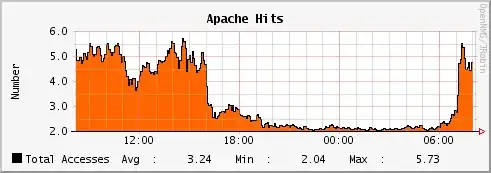
The remaining 2 hits per second throughout the night are induced by HAProxy checks - it runs HEAD http://mydomain.example.com/running HTTP/1.0 requests against the server every half a second with "running" being a static file (i.e. not invoking any perl code). It also seems that disabling these checks remedies the memory usage problem, but obviously cannot be a solution.
All of 3 similarly configured servers (behind HAProxy) expose this behavior. The running OS is Ubuntu 10.10, Apache version 2.2.16. This seems to be a memory leak but I have no idea how to start debugging it - any hints?