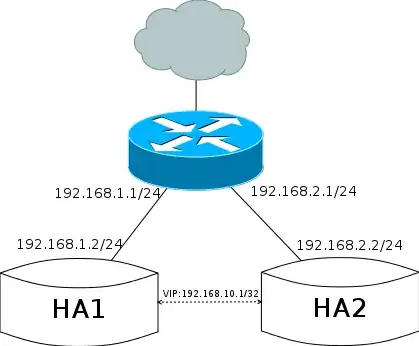
I'm going to setup redundant failover Redmine:
- another instance was installed on the second server without problem
- MySQL (running on the same machine with Redmine) was configured as master-master replication
Because they are in different subnet (192.168.3.x and 192.168.6.x), it seems that VIPArip is the only choice.
/etc/ha.d/ha.cf on node1
logfacility none
debug 1
debugfile /var/log/ha-debug
logfile /var/log/ha-log
autojoin none
warntime 3
deadtime 6
initdead 60
udpport 694
ucast eth1 node2.ip
keepalive 1
node node1
node node2
crm respawn
/etc/ha.d/ha.cf on node2:
logfacility none
debug 1
debugfile /var/log/ha-debug
logfile /var/log/ha-log
autojoin none
warntime 3
deadtime 6
initdead 60
udpport 694
ucast eth0 node1.ip
keepalive 1
node node1
node node2
crm respawn
crm configure show:
node $id="6c27077e-d718-4c82-b307-7dccaa027a72" node1
node $id="740d0726-e91d-40ed-9dc0-2368214a1f56" node2
primitive VIPArip ocf:heartbeat:VIPArip \
params ip="192.168.6.8" nic="lo:0" \
op start interval="0" timeout="20s" \
op monitor interval="5s" timeout="20s" depth="0" \
op stop interval="0" timeout="20s" \
meta is-managed="true"
property $id="cib-bootstrap-options" \
stonith-enabled="false" \
dc-version="1.0.12-unknown" \
cluster-infrastructure="Heartbeat" \
last-lrm-refresh="1338870303"
crm_mon -1:
============
Last updated: Tue Jun 5 18:36:42 2012
Stack: Heartbeat
Current DC: node2 (740d0726-e91d-40ed-9dc0-2368214a1f56) - partition with quorum
Version: 1.0.12-unknown
2 Nodes configured, unknown expected votes
1 Resources configured.
============
Online: [ node1 node2 ]
VIPArip (ocf::heartbeat:VIPArip): Started node1
ip addr show lo:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet 192.168.6.8/32 scope global lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
I can ping 192.168.6.8 from node1 (192.168.3.x):
# ping -c 4 192.168.6.8
PING 192.168.6.8 (192.168.6.8) 56(84) bytes of data.
64 bytes from 192.168.6.8: icmp_seq=1 ttl=64 time=0.062 ms
64 bytes from 192.168.6.8: icmp_seq=2 ttl=64 time=0.046 ms
64 bytes from 192.168.6.8: icmp_seq=3 ttl=64 time=0.059 ms
64 bytes from 192.168.6.8: icmp_seq=4 ttl=64 time=0.071 ms
--- 192.168.6.8 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.046/0.059/0.071/0.011 ms
but cannot ping virtual IP from node2 (192.168.6.x) and outside. Did I miss something?
PS: you probably want to set IP2UTIL=/sbin/ip in the /usr/lib/ocf/resource.d/heartbeat/VIPArip resource agent script if you get something like this:
Jun 5 11:08:10 node1 lrmd: [19832]: info: RA output: (VIPArip:stop:stderr) 2012/06/05_11:08:10 ERROR: Invalid OCF_RESK EY_ip [192.168.6.8]
http://www.clusterlabs.org/wiki/Debugging_Resource_Failures
Reply to @DukeLion:
Which router receives RIP updates?
When I start the VIPArip resource, ripd was run with below configuration file (on node1):
/var/run/resource-agents/VIPArip-ripd.conf:
hostname ripd
password zebra
debug rip events
debug rip packet
debug rip zebra
log file /var/log/quagga/quagga.log
router rip
!nic_tag
no passive-interface lo:0
network lo:0
distribute-list private out lo:0
distribute-list private in lo:0
!metric_tag
redistribute connected metric 3
!ip_tag
access-list private permit 192.168.6.8/32
access-list private deny any
show ip route:
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, A - Babel,
> - selected route, * - FIB route
K>* 0.0.0.0/0 via 192.168.3.1, eth1
C>* 127.0.0.0/8 is directly connected, lo
K>* 169.254.0.0/16 is directly connected, eth1
C>* 192.168.3.0/24 is directly connected, eth1
C>* 192.168.6.8/32 is directly connected, lo
sh ip rip status:
Routing Protocol is "rip"
Sending updates every 30 seconds with +/-50%, next due in 7 seconds
Timeout after 180 seconds, garbage collect after 120 seconds
Outgoing update filter list for all interface is not set
lo:0 filtered by private
Incoming update filter list for all interface is not set
lo:0 filtered by private
Default redistribution metric is 1
Redistributing: connected
Default version control: send version 2, receive any version
Interface Send Recv Key-chain
Routing for Networks:
lo:0
Routing Information Sources:
Gateway BadPackets BadRoutes Distance Last Update
Distance: (default is 120)