Let me preface this by saying that this is a followup question to this topic.
That was "solved" by switching from Solaris (SmartOS) to Ubuntu for the memcached server. Now we've multiplied load by about 5x and are running into problems again.
We are running a site that is doing about 1000 requests/minute, each request hits Memcached with approximately 3 reads and 1 write. So load is approximately 65 requests per second. Total data in the cache is about 37M, and each key contains a very small amount of data (a JSON-encoded array of integers amounting to less than 1K).
We have setup a benchmarking script on these pages and fed the data into StatsD for logging. The problem is that there are spikes where Memcached takes a very long time to respond. These do not appear to correlate with spikes in traffic.
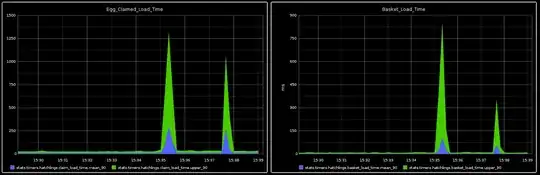
What could be causing these spikes? Why would memcached take over a second to reply? We just booted up a second server to put in the pool and it didn't make any noticeable difference in the frequency or severity of the spikes.
This is the output of getStats() on the servers:
Array
(
[-----------] => Array
(
[pid] => 1364
[uptime] => 3715684
[threads] => 4
[time] => 1336596719
[pointer_size] => 64
[rusage_user_seconds] => 7924
[rusage_user_microseconds] => 170000
[rusage_system_seconds] => 187214
[rusage_system_microseconds] => 190000
[curr_items] => 12578
[total_items] => 53516300
[limit_maxbytes] => 943718400
[curr_connections] => 14
[total_connections] => 72550117
[connection_structures] => 165
[bytes] => 2616068
[cmd_get] => 450388258
[cmd_set] => 53493365
[get_hits] => 450388258
[get_misses] => 2244297
[evictions] => 0
[bytes_read] => 2138744916
[bytes_written] => 745275216
[version] => 1.4.2
)
[-----------:11211] => Array
(
[pid] => 8099
[uptime] => 4687
[threads] => 4
[time] => 1336596719
[pointer_size] => 64
[rusage_user_seconds] => 7
[rusage_user_microseconds] => 170000
[rusage_system_seconds] => 290
[rusage_system_microseconds] => 990000
[curr_items] => 2384
[total_items] => 225964
[limit_maxbytes] => 943718400
[curr_connections] => 7
[total_connections] => 588097
[connection_structures] => 91
[bytes] => 562641
[cmd_get] => 1012562
[cmd_set] => 225778
[get_hits] => 1012562
[get_misses] => 125161
[evictions] => 0
[bytes_read] => 91270698
[bytes_written] => 350071516
[version] => 1.4.2
)
)
Edit: Here is the result of a set and retrieve of 10,000 values.
Normal:
Stored 10000 values in 5.6118 seconds.
Average: 0.0006
High: 0.1958
Low: 0.0003
Fetched 10000 values in 5.1215 seconds.
Average: 0.0005
High: 0.0141
Low: 0.0003
When Spiking:
Stored 10000 values in 16.5074 seconds.
Average: 0.0017
High: 0.9288
Low: 0.0003
Fetched 10000 values in 19.8771 seconds.
Average: 0.0020
High: 0.9478
Low: 0.0003