I run a CentOS 5.7 64 machine with 24gb ram and running kernel 2.6.18-274.12.1.el5.
This machine runs only Nginx, php-fpm and Xcache as extra applications.
Since about 3 weeks my memory behavior on this machine has changed and I cannot explain why. There are no crons running which flush anything like this. There are also no large numbers of files being deleted/changed during these drops.
The 'cached' memory gets dropped about every few hours, but it's never a set gap between flushes, this indicates to me that some bottleneck gets reached instead. It also always seems to be when total memory usages gets to about 18GB, but again, not always exactly 18GB.
This is a graph of my memory usage: 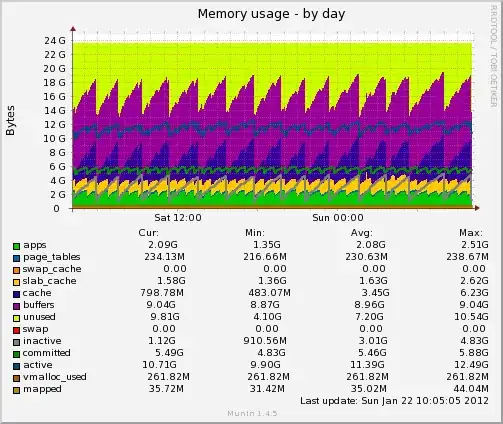
As you can see in the graph the 'buffers' always stay more or less the same, it is mainly the 'cache' that gets dropped.
Running vmstat -m I have outputted the memory usage just before and just after a memory drop. The output is here: http://pastebin.com/diff.php?i=hJqZqztm 'old version' being before, 'new version' being after a drop.
About 3 weeks ago my server crashed during a heavy DDOS attack, after I rebooted the machine this odd behavior started. I have checked a bunch of logs, restarted the machine again, and cannot find any indication what changed.
During these 'cache' memory drops, my iNode usage drops at the same time.
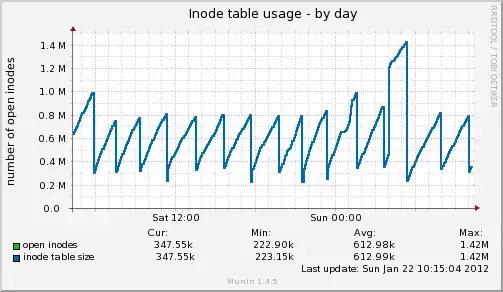
Does anyone have any idea what might be causing this behavior? Clearly my RAM isn't full, so I am curious why this could be happening.