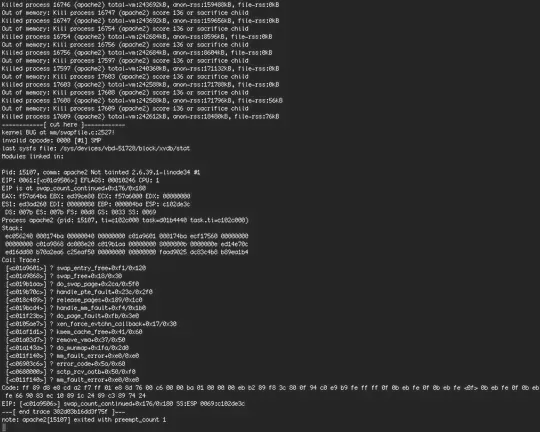
I have a VPS with Linode right now. I was alerted by my monitoring service that a site I was hosting had gone down. I used Lish, Linode's method of getting direct out-of-band access to the console over an SSH connection but without using SSH, to see any error messages. This is what I saw:
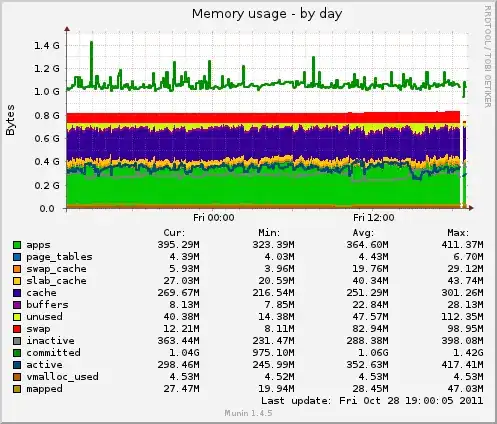
I checked my Munin logs to see if there was a spike in memory usage, and indeed there is a spike at the appropriate time for the swap graph:
However, there was no spike on the memory graph (although swap does seem to be rising slightly):
I restarted the server and it has been working fine since. I checked Apache access and error logs and saw nothing suspicious. The last entry in syslog prior to the server restart was an error with the IMAP daemon and does not appear to be related:
Oct 28 18:30:35 hostname imapd: TIMEOUT, user=user@xxxxxxxxxxxxx.com, ip=[::ffff:XX.XX.XX.XX], headers=0, body=0, rcvd=195, sent=680, time=1803
# all of the startup logs below here
Oct 28 18:40:33 hostname kernel: imklog 5.8.1, log source = /proc/kmsg started.
I tried checking dmesg but didn't see anything suspicious either. The last few lines:
VFS: Mounted root (ext3 filesystem) readonly on device 202:0. devtmpfs: mounted Freeing unused kernel memory: 412k freed Write protecting the kernel text: 5704k Write protecting the kernel read-only data: 1384k NX-protecting the kernel data: 3512k init: Failed to spawn console-setup main process: unable to execute: No such file or directory udevd[1040]: starting version 173 Adding 524284k swap on /dev/xvdb. Priority:-1 extents:1 across:524284k SS init: udev-fallback-graphics main process (1979) terminated with status 1 init: plymouth main process (1002) killed by SEGV signal init: plymouth-splash main process (1983) terminated with status 2 EXT3-fs (xvda): using internal journal init: plymouth-log main process (2017) terminated with status 1 init: plymouth-upstart-bridge main process (2143) terminated with status 1 init: ssh main process (2042) terminated with status 255 init: failsafe main process (2018) killed by TERM signal init: apport pre-start process (2363) terminated with status 1 init: apport post-stop process (2371) terminated with status 1
I tried Googling the error message (kernel BUG at mm/swapfile.c:2527!) and found a few Xen related topics (Linode uses Xen):
- Xen-devel Re: kernel BUG at mm/swapfile.c:2527! was 3.0.0 Xen - Xen Source
- Mailing List Archive: Re: Re: kernel BUG at mm/swapfile.c:2527! was 3.0.0 Xen pv guest - BUG: Unable to handle
However, none of the information I found seemed to point to any solution. I am going to upgrade to the latest kernel Linode offers (from 2.6.39.1-linode34 to 3.0.4-linode38).
Is there anything else I can do to diagnose this problem now, or in the future if it should happen again? Is there anything I missed? Does anybody have ideas for what may have triggered this?
Please let me know if there's any other information I can provide. Thanks a ton.