This question is reposted from Stack Overflow based on a suggestion in the comments, apologies for the duplication.
Questions
Question 1: as the size of the database table gets larger how can I tune MySQL to increase the speed of the LOAD DATA INFILE call?
Question 2: would using a cluster of computers to load different csv files, improve the performance or kill it? (this is my bench-marking task for tomorrow using the load data and bulk inserts)
Goal
We are trying out different combinations of feature detectors and clustering parameters for image search, as a result we need to be able to build and big databases in a timely fashion.
Machine Info
The machine has 256 gig of ram and there are another 2 machines available with the same amount of ram if there is a way to improve the creation time by distributing the database?
Table Schema
the table schema looks like
+---------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+------------------+------+-----+---------+----------------+
| match_index | int(10) unsigned | NO | PRI | NULL | |
| cluster_index | int(10) unsigned | NO | PRI | NULL | |
| id | int(11) | NO | PRI | NULL | auto_increment |
| tfidf | float | NO | | 0 | |
+---------------+------------------+------+-----+---------+----------------+created with
CREATE TABLE test
(
match_index INT UNSIGNED NOT NULL,
cluster_index INT UNSIGNED NOT NULL,
id INT NOT NULL AUTO_INCREMENT,
tfidf FLOAT NOT NULL DEFAULT 0,
UNIQUE KEY (id),
PRIMARY KEY(cluster_index,match_index,id)
)engine=innodb;Benchmarking so far
First step was to compare bulk inserts vs loading from a binary file into an empty table.
It took: 0:09:12.394571 to do 4,000 inserts with 5,000 rows per insert
It took: 0:03:11.368320 seconds to load 20,000,000 rows from a csv fileGiven the difference in performance I have gone with loading the data from a binary csv file, first I loaded binary files containing 100K, 1M, 20M, 200M rows using the call below.
LOAD DATA INFILE '/mnt/tests/data.csv' INTO TABLE test;I killed the 200M row binary file (~3GB csv file) load after 2 hours.
So I ran a script to create the table, and insert different numbers of rows from a binary file then drop the table, see the graph below.
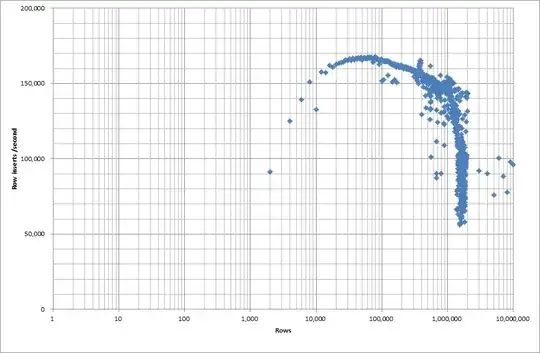
It took about 7 seconds to insert 1M rows from the binary file. Next I decided to benchmark inserting 1M rows at a time to see if there was going to be a bottleneck at a particular database size. Once the Database hit approximately 59M rows the average insert time dropped to approximately 5,000/second
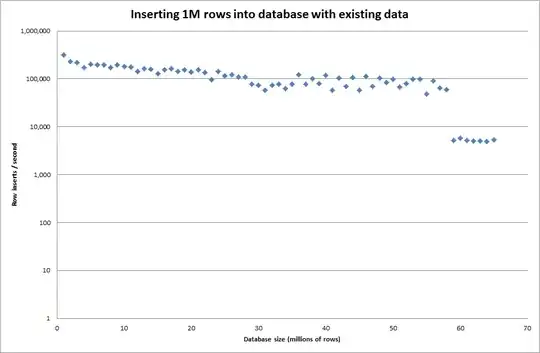
Setting the global key_buffer_size = 4294967296 improved the speeds slightly for inserting smaller binary files. The graph below shows the speeds for different numbers of rows
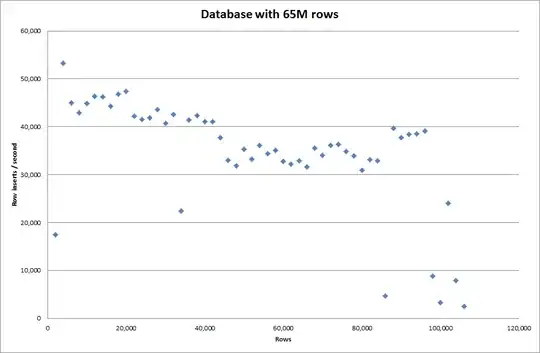
However for inserting 1M rows it didn't improve the performance.
rows: 1,000,000 time: 0:04:13.761428 inserts/sec: 3,940
vs for an empty database
rows: 1,000,000 time: 0:00:6.339295 inserts/sec: 315,492
Update
Doing the load data using the following sequence vs just using the load data command
SET autocommit=0;
SET foreign_key_checks=0;
SET unique_checks=0;
LOAD DATA INFILE '/mnt/imagesearch/tests/eggs.csv' INTO TABLE test_ClusterMatches;
SET foreign_key_checks=1;
SET unique_checks=1;
COMMIT;
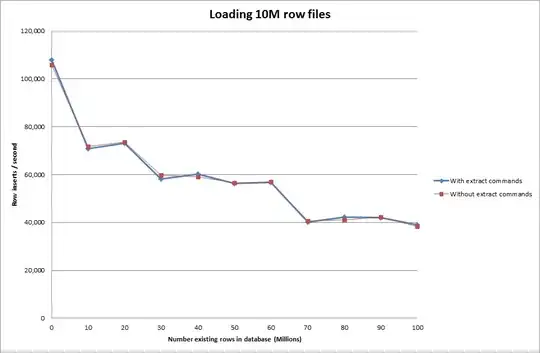
So this looks quite promising in terms of the database size that is being generated but the other settings don't appear to affect the performance of the load data infile call.
I then tried loading multiple files from different machines but the load data infile command locks the table, due to the large size of the files causing the other machines to time out with
ERROR 1205 (HY000) at line 1: Lock wait timeout exceeded; try restarting transactionIncreasing the number of rows in binary file
rows: 10,000,000 seconds rows: 0:01:36.545094 inserts/sec: 103578.541236
rows: 20,000,000 seconds rows: 0:03:14.230782 inserts/sec: 102970.29026
rows: 30,000,000 seconds rows: 0:05:07.792266 inserts/sec: 97468.3359978
rows: 40,000,000 seconds rows: 0:06:53.465898 inserts/sec: 96743.1659866
rows: 50,000,000 seconds rows: 0:08:48.721011 inserts/sec: 94567.8324859
rows: 60,000,000 seconds rows: 0:10:32.888930 inserts/sec: 94803.3646283Solution: Precomputing the id outside of MySQL instead of using auto increment
Building the table with
CREATE TABLE test (
match_index INT UNSIGNED NOT NULL,
cluster_index INT UNSIGNED NOT NULL,
id INT NOT NULL ,
tfidf FLOAT NOT NULL DEFAULT 0,
PRIMARY KEY(cluster_index,match_index,id)
)engine=innodb;with the SQL
LOAD DATA INFILE '/mnt/tests/data.csv' INTO TABLE test FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';"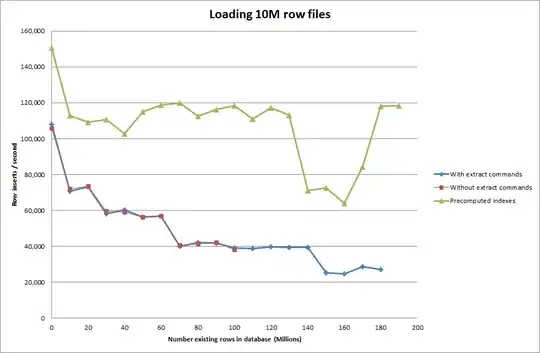
Getting the script to pre-compute the indexes appears to have removed the performance hit as the database grows in size.
Update 2 - using memory tables
Roughly 3 times faster, without taking into account the cost of moving an in-memory table to disk-based table.
rows: 0 seconds rows: 0:00:26.661321 inserts/sec: 375075.18851
rows: 10000000 time: 0:00:32.765095 inserts/sec: 305202.83857
rows: 20000000 time: 0:00:38.937946 inserts/sec: 256818.888187
rows: 30000000 time: 0:00:35.170084 inserts/sec: 284332.559456
rows: 40000000 time: 0:00:33.371274 inserts/sec: 299658.922222
rows: 50000000 time: 0:00:39.396904 inserts/sec: 253827.051994
rows: 60000000 time: 0:00:37.719409 inserts/sec: 265115.500617
rows: 70000000 time: 0:00:32.993904 inserts/sec: 303086.291334
rows: 80000000 time: 0:00:33.818471 inserts/sec: 295696.396209
rows: 90000000 time: 0:00:33.534934 inserts/sec: 298196.501594
by loading the data into a memory based table and then copying it to a disk based table in chunks had an overhead of 10 min 59.71 sec to copy 107,356,741 rows with the query
insert into test Select * from test2;
which makes it approximately 15 minutes to load 100M rows, which is approximately the same as directly inserting it into a disk based table.