The last few weeks, we've been getting this kernel panic on one machine or another out of a cluster of 15, about one every four days. The machines are all running Ubuntu 10.04 LTS with Erlang R13B03; the machines have dual quad-core hyper-threaded Xeon E5520 CPUs.
The crash stack looks like the attached picture (which we had our co-lo provider send us from the crashed console):
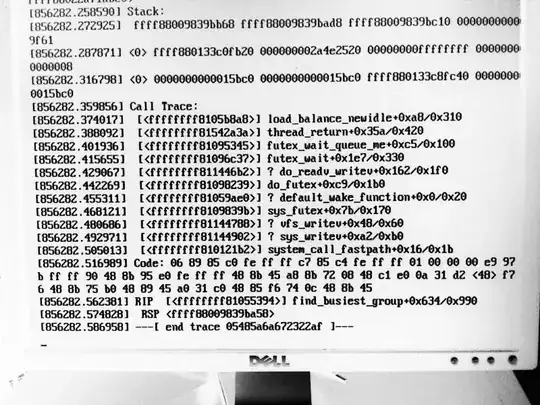
The linux version is:
Linux AF001783 2.6.32-28-generic #55-Ubuntu SMP Mon Jan 10 23:42:43 UTC 2011 x86_64 GNU/Linux
The weird thing is, these hosts have been running without this problem for a year before now, and the load profile is not significantly different from before. And it's not just a single host, in which case I'd suspect bad hardware.