I have a server running VMware ESXi v4.1.0 348481. It has a hardware RAID10 and a SATA backup drive. I have a VM running which has it's primary boot vmdk on the RAID10 datastore, and a 600 GB vmdk on the SATA backup drive's datastore. The VM runs Debian linux with the FreeBSD kernel, and uses ZFS for the backup drive.
EDIT: The drive is not directly attached to the VM. It is used as a VMware Datastore, and the VM has a vmdk on the SATA drive's datastore. The datastore is not full (only 65% full)
I logged in to the server using SSH and found that last night backup was hung, and zfs list or zpool list both hung. So I opened the virtual console in ESXi and was sad to see:
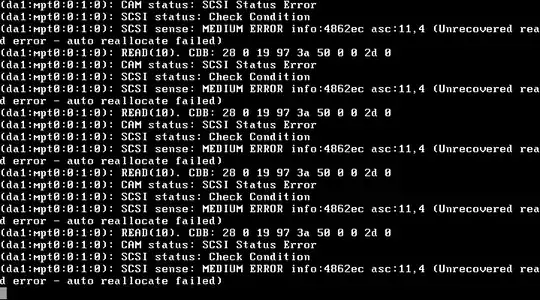
(da1:mpt0:0:1:0): READ(10). CDC: 28 0 19 97 3a 50 0 0 2d 0
(da1:mpt0:0:1:0): CAM status: SCSI Status Error
(da1:mpt0:0:1:0): SCSI status: Check Condition
(da1:mpt0:0:1:0): SCSI sense: MEDIUM ERROR info:4862ec asc:11,4 (Unrecovered read error - auto reallocate failed)
(da1:mpt0:0:1:0): READ(10). CDC: 28 0 19 97 3a 50 0 0 2d 0
(da1:mpt0:0:1:0): CAM status: SCSI Status Error
(da1:mpt0:0:1:0): SCSI status: Check Condition
(da1:mpt0:0:1:0): SCSI sense: MEDIUM ERROR info:4862ec asc:11,4 (Unrecovered read error - auto reallocate failed)
I tried to reboot the VM and I received a message that the system was going down for reboot, and then that hung. (^C appears but does not kill shutdown). I cannot interrupt or kill -9 the zpool list zfs list or rsync processes -- Nothing happens when I try.
- Does this ndicate the backup SATA drive is failing? Or could this just be an ESXi error?
- How in the vSphere client could I tell if the drive is failing? I didn't see any indication, everything under Hardware Health Status looks good, and I saw nothing under the Storage config.
- How should I proceed from here? Should I just hard reboot the VM?
UPDATE: I just hard rebooted the VM. After it came back online, the backup zpool was online, however:
root@timestandstill:/home/jnet# zpool status -v
pool: backup
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://www.sun.com/msg/ZFS-8000-8A
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
backup ONLINE 0 0 0
da1 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
/backups/someserver/home/someuser/public_html/somedir/calendar/someuser/calendars/somefile.ics
I am leaning heavily towards replacing the drive...