We had some trouble with one of our image servers last week and need some help. See our munin monitoring graph:
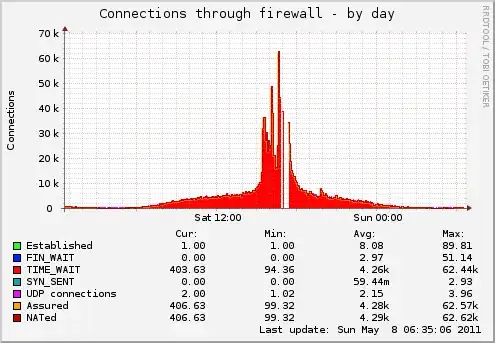
We are runing debian squeeze and we have lots of requests because this is one of our image servers. We do not use keep-alive (maybe we should, but that's another topic)
These numbers are request counts per minute from our log files:
- 17:19: 66516
- 17:20: 64627
- 17:21: 123365
- 17:22: 111207
- 17:23: 58257
- 17:24: 17710
- ... and so on
So you see, we have lots of requests per minute but as most request are served in 0-1ms everything runs fine usually.
Now as you see in our munin graphic munin didn't manage to connect to this server on munin port and ask the relevant numbers. The connection simply failed. As the server is not overloaded by any means (cpu, memory, network). it must has something to do with our firewall/tcp stack. At the time the munin plugin failed to connect we had only 17MBit of incoming and outgoing traffic on a 100MBit connection.
you often here a limit of 65k of tcp connections, but this is normally misleading as it refers to the 16bit tcp header and belongs to 65k per ip/port combination.
our time_wait timeout is set to
net.ipv4.tcp_fin_timeout = 60
we could lower this to drop more TIME_WAIT connections earlier, but first i want to know what limits the network from being reachable.
we are using iptables with state module. But we already raised the max_conntrack parameter.
net.ipv4.netfilter.ip_conntrack_max = 524288
does anybody know what kernel parameters to look at or how to diagnose this problem next week when we have our next peek?