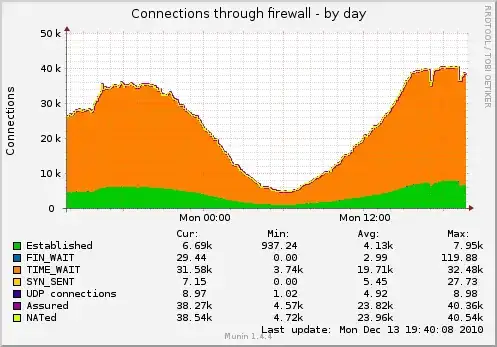
One thing you should do to start is to fix the net.ipv4.tcp_fin_timeout=1. That is way to low, you should probably not take that much lower than 30.
Since this is behind nginx. Does that mean nginx is acting as a reverse proxy? If that is the case then your connections are 2x (one to client, one to your web servers). Do you know which end these sockets belong to?
Update:
fin_timeout is how long they stay in FIN-WAIT-2 (From networking/ip-sysctl.txt in the kernel documentation):
tcp_fin_timeout - INTEGER
Time to hold socket in state FIN-WAIT-2, if it was closed
by our side. Peer can be broken and never close its side,
or even died unexpectedly. Default value is 60sec.
Usual value used in 2.2 was 180 seconds, you may restore
it, but remember that if your machine is even underloaded WEB server,
you risk to overflow memory with kilotons of dead sockets,
FIN-WAIT-2 sockets are less dangerous than FIN-WAIT-1,
because they eat maximum 1.5K of memory, but they tend
to live longer. Cf. tcp_max_orphans.
I think you maybe just have to let Linux keep the TIME_WAIT socket number up against what looks like maybe 32k cap on them and this is where Linux recycles them. This 32k is alluded to in this link:
Also, I find the
/proc/sys/net/ipv4/tcp_max_tw_buckets
confusing. Although the default is set
at 180000, I see a TCP disruption when
I have 32K TIME_WAIT sockets on my
system, regardless of the max tw
buckets.
This link also suggests that the TIME_WAIT state is 60 seconds and can not be tuned via proc.
Random fun fact:
You can see the timers on the timewait with netstat for each socket with netstat -on | grep TIME_WAIT | less
Reuse Vs Recycle:
These are kind of interesting, it reads like reuse enable the reuse of time_Wait sockets, and recycle puts it into TURBO mode:
tcp_tw_recycle - BOOLEAN
Enable fast recycling TIME-WAIT sockets. Default value is 0.
It should not be changed without advice/request of technical
experts.
tcp_tw_reuse - BOOLEAN
Allow to reuse TIME-WAIT sockets for new connections when it is
safe from protocol viewpoint. Default value is 0.
It should not be changed without advice/request of technical
experts.
I wouldn't recommend using net.ipv4.tcp_tw_recycle as it causes problems with NAT clients.
Maybe you might try not having both of those switched on and see what effect it has (Try one at a time and see how they work on their own)? I would use netstat -n | grep TIME_WAIT | wc -l for faster feedback than Munin.