I believe everything I've linked is safe. Sorry for the format, I'll try to fix this when I can.
Here are some candidates with similarly large metadata counts. Report links come from Googling "Excessive number of items for * DocumentAncestors" (which comes from exiftool, apparently used by VirusTotal).
Here's a jpg or mp3 (report), a png with spam text (report), a png alone (report), and two with the same md5 (31a02712515ace35f1a593c14a7b5150), but this one starts with "0," like your example does. png (report) and a live sample png samsung tablet (SAMPLE). The sample comes from the hash; the others did not produce samples.
A histogram from the "samsung" sample (I quickly split out each byte of 107,000 entries, sorted and sent them through 'uniq') may be of limited utility, except to show that the bytes aren't completely random. This may be expected given how some operations are probably encoded, but I was assuming a programming error that generated purely random UUIDs. This isn't the prettiest picture so I can work on that. Decimal 17 (0x11) is the large spike at bottom.
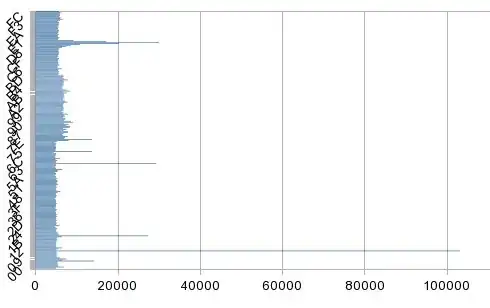
I tried some experiments to see if there might be some encoded data (also the point of the histogram) but have mostly approached it as just metadata generated while a file is processed.
Here are some additional pursuits:
Another forum post at Adobe Photoshop CC is creating problematic JPEGs that make OSX Preview.app lose its mind with a linked file (Note4Cover1.jpg) that's just as large but not as nicely formatted inside.
Someone else with an excessive number of items, I think this link suggests how to remove the extra data (warning that it may remove stuff you want):
exiftool -xmp:all= -tagsfromfile @ "-all:all<xmp:all" FILE
A caveat: I found that opening and saving with a new name using GIMP removed the data regardless of the checkboxes being set to save it. It seems like that's not supposed to happen according to the standards linked by other answers here.
And finally, differ (differ.readthedocs.org) is an image reporting library. I haven't evaluated it because while it looks useful and dumps stats from may tools (like exiftool and imagemagick) it might be a little tricky to set up (github). It still might be useful for forensic data.
{kind=link}