Although modern x86 processors allow for runtime microcode upload, the format is model-specific, undocumented, and controlled by checksums and possibly signatures. Also, the scope of microcode is somewhat limited nowadays, because most instructions are hardwired. See this answer for some details. Modern operating systems upload microcode blocks upon boot, but these blocks are provided by the CPU vendors themselves for bugfixing purposes.
(Note that microcode which is uploaded is kept in an internal dedicated RAM block, which is not Flash or EEPROM; it is lost when power is cut.)
Update: there seems to be some misconceptions and/or terminology confusion about what microcode is and what it can do, so here are some longer explanations.
In the days of the first microprocessors, transistors were expensive: they used a lot of silicon area, which is the scarce resource in chip foundries (the larger a chip is, the higher the failure rate, because each dust particle at the wrong place makes the whole chip inoperative). So the chip designers had to resort to many tricks, one of them being microcode. The architecture of a chip of that era would look like this:
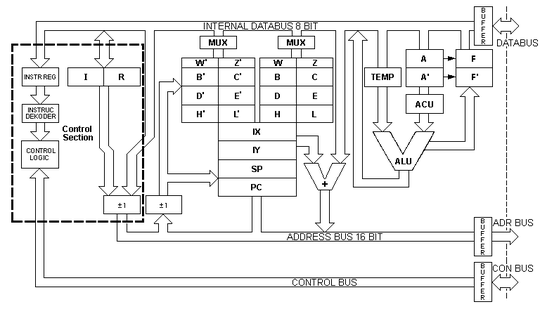
(this image was shamelessly plundered from this site). The CPU is segmented into many individual units linked together through data buses. Let's see what a fictional "add B, C" instruction would entail (addition of the contents of register B and register C, result to be stored back in B):
- The register bank must put the contents of the B register on the internal data bus. At the end of the same cycle, the "TEMP" storage unit should read the value from the data bus and store it.
- The register bank must put the contents of the C register on the internal data bus. At the end of the same cycle, the "A" storage unit should read the value from the data bus and store it.
- The Arithmetic and Logic Unit (ALU) should read its two inputs (which are TEMP and A) and compute an addition. The result will be available on its output at the next cycle on the bus.
- The register bank must read the byte on the internal data bus, and store it into the B register.
The whole process would take a whooping four clock cycles. Each unit in the CPU must receive its specific orders in due sequence. The control unit, which dispatches the activation signals to each CPU unit, must "know" all the sequences for all the instruction. This is where microcode intervenes. Microcode is a representation, as bit words, of elementary steps in this process. Each CPU unit would have a few reserved bits in each microcode. For instance, bits 0 to 3 in each word would be for the register bank, encoding the register which is to be operated, and whether the operation is a read or a write; bits 4 to 6 would be for the ALU, telling it which arithmetic or logic operation it must perform.
With microcode, the control logic becomes a rather simple circuit: it consists of a pointer in the microcode (which is a ROM block); at each cycle, the control unit reads the next microcode word, and sends to each CPU unit, on dedicated wires, its microcode bits. The instruction decoder is then a map from opcodes (the "machine code instructions" which the programmer sees, and are stored in RAM) into offsets in the microcode block: the decoder sets the microcode pointer to the first microcode word for the sequence which implements the opcode.
One description of this process is that the CPU really processes microcode; and the microcode implements an emulator for the actual opcodes which the programmer thinks of as "machine code".
ROM is compact: each ROM bit takes about the same size, or even slightly less, than one transistor. This allowed the CPU designers to store a lot of complex distinct behaviours in a small silicon space. Thus, the highly venerable Motorola 68000 CPU, core processor of the Atari ST, Amiga and Sega Megadrive, could fit in about 40000 transistor-equivalent space, about a third of which consisting of microcode; in that tiny area, it could host fifteen 32-bit registers, and implement a whole paraphernalia of addressing modes for which is was famous. The opcodes were reasonably compact (thus saving RAM); microcode words are larger, but invisible from the outside.
All this changed with the advent of the RISC processors. RISC comes from the realization that while microcode allows for opcodes with complex behaviour, it also implies a lot of overhead in instruction decoding. As we saw above, a simple addition would take several clock cycles. On the other hand, programmers of that time (late 1980s) would increasingly shun assembly, preferring the use of compilers. A compiler translates some programming language into a sequence of opcodes. It so happens that compilers use relatively simple opcodes; opcodes with complex behaviour are hard to integrate into the logic of a compiler. So the net result was that microcode implied overhead, thus execution inefficiency, for the sake of complex opcodes which the programmers did not use !
RISC is, simply put, the suppression of the microcode-in-CPU. The opcodes which the programmer (or the compiler) sees are the microcode, or close enough. This means that RISC opcodes are larger (typically 32 bits per opcode, as in the original ARM, Sparc, Mips, Alpha and PowerPC processors) with a more regular encoding. A RISC CPU can then process one instruction per cycle. Of course, instructions do less things than their CISC counterparts ("CISC" is what non-RISC processors do, like the 68000).
Therefore, if you want to program in microcode, use a RISC processor. In a true RISC processor, there is no microcode stricto sensu; there are opcodes which are translated with a 1-to-1 correspondence into the activation bits for all the CPU units. This gives the compiler more options to optimize code, while saving space in the CPU. The first ARM used only 30000 transistors, less than the 68000, while providing substantially more computing power for the same clock frequency. The price to pay was larger code, but RAM was increasingly cheaper at that time (that's when computer RAM size began to be counted in megabytes instead of mere kilobytes).
Then things changed again by becoming more confused. RISC did not kill off the CISC processors. It turned out that backward compatibility is an extremely strong force in the computing industry. This is why modern x86 processors (like Intel i7 or even newer) are still able to run code designed for the 8086 of the late 1970s. So x86 processors have to implement opcodes with complex behaviours. The result is that modern processors have an instruction decoder which segregates opcodes into two categories:
- The usual, simple opcodes which compilers use are executed RISC-like, "hardwired" into fixed behaviours. Additions, multiplications, memory accesses, control flow opcodes... are all handled that way.
- The unusual, complex opcodes kept around for compatibility are interpreted with microcode, which is limited to a subset of the units in the CPU so as not to interfere and induce latency in the processing of the simple opcodes. An example of a microcoded instruction in a modern x86 is
fsin, which computes the sine function on a floating-point operand.
Since transistors have shrunk a lot (a quad-core i7 from 2008 uses 731 millions of transistors), it became quite tolerable to replace the ROM block for microcode with a RAM block. That RAM block is still internal to the CPU, inaccessible from user code, but it can be updated. After all, microcode is a kind of software, so it has bugs. CPU vendors publish updates for the microcode of their CPU. Such an update can be uploaded by the operating system using some specific opcodes (this requires kernel-level privileges). Since we are talking about RAM, this is not permanent, and must be performed again after each boot.
The contents of these microcode updates are not documented at all; they are very specific to the CPU exact model, and there is no standard. Moreover, there are checksums which are believed to be MAC or possibly even digital signatures: vendors want to keep a tight control of what enters the microcode area. It is conceivable that maliciously crafted microcode could damage the CPU by triggering "short circuits" within the CPU.
Summary: microcode is not as awesome as what it is often cracked up to be. Right now, microcode hacking is a closed area; CPU vendors reserve it for themselves. But even if you could write your own microcode, you would probably be disappointed: in modern CPU, microcode impacts only peripheral units of the CPU.
As for the initial question, an "obscure opcode behaviour" implemented in microcode would not be practically different from a custom virtual machine emulator, like what @Christian links to. It would be "security through obscurity" at its finest, i.e. not very fine. Such things are vulnerable to reverse engineering.
If the fabled microcode could implement a complete decryption engine with a tamper resistant storage area for keys, then you could have a really robust anti-reverse-engineering solution. But microcode cannot do that. This requires some more hardware. The Cell CPU can do that; it has been used in the Sony PS3 (Sony botched it in other areas, though -- the CPU is not alone in the system and cannot ensure total security by itself).