Information entropy only applies as a measure when the characters are chosen randomly and uniformly. Choosing the first letter of each word in the sentence is inherently non-random and non-uniform, so you cannot calculate the entropy of passwords generated by this scheme. Any estimation would be a gross simplification to the point of being misleading.
Since what you're really asking is "how hard is this to crack compared to a randomly chosen uniform distribution of letters?", let's consider the problem of how to answer that, instead of trying to apply a metric that isn't applicable.
The first thing we might want to know is the relative frequencies of the first letter of words in the English language. This alone does not have a clear answer, since "English words" is a poorly defined set. The list of words in the dictionary is one source, but that doesn't account for words that aren't commonly listed in the dictionary, nor does it account for the frequency of use of the words. Words appear once each in the dictionary, but with varying frequency in real sentences. Many words in the dictionary are obscure and are extremely unlikely to appear in a sentence chosen by a user.
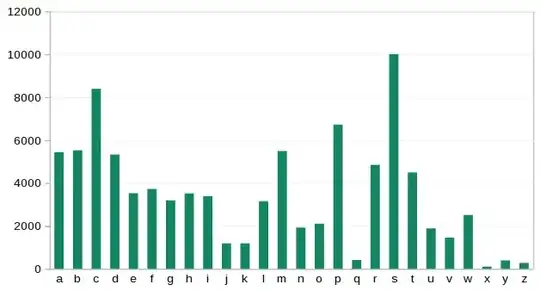
Wikipedia has a table of letter frequencies that lists the relative frequencies of the first letter of English words as appearing in texts. The distribution is as follows:
T 16%
A 11.7%
O 7.6%
I 7.3%
S 6.7%
W 5.5%
C 5.2%
B 4.4%
P 4.3%
H 4.2%
F 4%
M 3.8%
D 3.2%
E 2.8%
R 2.8%
L 2.4%
N 2.3%
G 1.6%
U 1.2%
K 0.86%
V 0.82%
Y 0.76%
J 0.51%
Q 0.22%
X 0.045%
Z 0.045%
Sounds promising, right? Except it isn't all that useful. The probability of having a particular letter as the first letter of a word varies wildly based on that word's position in a sentence. On top of that, until now we've made the assumption that the probability of having a particular letter at the start of the word is independent, but it is not. The distribution not only varies upon the position of the word in the sentence, but also the word that came before it, and the word before that.
What this does mean, though, is that we can build our own custom dictionary based on a large corpus of text. I grabbed the OANC corpus for my own tests, but a better corpus could be generated using a large library of famous quotes, song lyrics, meme formats, popular tweets, etc.
The wordlist building approach is as follows:
- Take the contents of every text file and read it line by line.
- Trim leading and trailing whitespace from each line.
- Concatenate all lines together with a space between them, into one long unbroken string.
- Utilise a sentence-splitting regex to recover the component sentences from that string.
- Normalise the sentences to remove punctuation.
- Extract the first letter of each word in each sentence, in order, and build a character sequence from it.
- If the sequence is between 6 and 20 characters (i.e. a sentence with between 6 and 20 words), add it to the sequence list.
- Once the sequence list is built, sort it alphabetically.
- Count the occurrences of each entry in the list and sort the list by that count, descending.
For a ~3GB corpus of plaintext, this process takes around 30 seconds. The OANC corpus contains around 550,000 sentences, producing a first-letters wordlist of approximately 400,000 unique entries.
Given that the brute-force search space for a 6 character lowercase alpha password is around 300 million, this implies that the search space reduction caused by this first-letter scheme is very significant, bringing it within range of a trivial dictionary attack once the corpus is built.
Since humans are most likely to pick sentences of interest, rather than obscure sentences or anything close to truly random, and sentences of interest that have enough words to meet the length ranges required for passwords are fewer still, the likelihood of breaking this scheme given a reasonable source of popular phrases is fairly excellent.
As a bonus, I did some trigram analysis on the sequences. A trigram is any sequence of three letters. For example, the sentence "the quick brown fox jumps over the lazy dog" would have a starting trigram of "tqb" and contain the trigrams "tqb qbf bfj fjo jot otl tld".
The 200 most common trigrams that occurred at the start of a sentence were as follows:
tia, iat, tao, tat, teo, taa, att, tst, tit, its, tpo, tso, itc, tro, tsa, tio, iia, tas, mot, tpa, tsi, tco, tsw, tai, itp, tii, ats, tpw, ata, ita, tpi, sot, trt, tcw, tra, tca, oot, tri, twa, tci, ttt, itt, iaa, oto, iit, aar, tta, tot, tps, ias, iot, ist, tmo, ato, tss, aot, ict, tto, tac, tct, atp, bta, bot, tin, toa, tdi, tma, ati, tti, aat, twt, tft, tmi, tdo, tcs, ite, ate, aaa, too, taw, tlo, tae, asi, tsc, tis, tfi, iwa, iti, tts, trs, tea, fet, tno, ait, tfa, atc, tar, tap, tet, tfo, tiw, wat, tsp, iae, iac, tpc, itm, tmt, tos, tic, tmw, trw, atm, iwt, tpt, itf, tms, ttc, ttw, bit, tam, tda, itr, tcc, iaw, ito, btt, aso, iin, bti, iai, ift, tte, tmc, tds, atw, tei, tah, aas, tad, ton, iii, itw, sao, ttp, twn, aia, tfs, toi, bts, atr, tdt, tmp, aft, bat, aii, iow, tor, ihb, irt, taf, tsh, tan, wit, saa, wta, iha, aac, tnt, tsr, aao, tpr, tuo, iht, eot, fta, tho, tha, itl, trc, aai, tdw, tla, wst, asa, iwb, fts, ast, bia, toc, not, tmb, tsf, iip, sat, fea, tsd, cwt, hia, ftr
These trigrams appeared 126173 times, making up 26.5% of the total. As such, for any given sentence you have a better than 1 in 4 chance of the first three letters of the sequence appearing on this list.
The 701 most frequent trigrams made up 50% of the occurrences. The other 50% of occurrences were comprised of 11392 trigrams.
Expanding this to look at all trigrams in the sequences, not just those appearing at the start of a sequence, the 200 most common were:
att, tat, aat, sot, tao, aaa, taa, aot, ata, teo, tso, tta, tpo, tst, tia, iat, tsa, ots, ttt, ota, tit, tco, pot, tot, its, sat, ait, ott, ats, tto, stt, cot, otc, ita, itt, oot, otp, tro, tca, ato, tct, tpa, eot, iaa, ttc, tts, itc, mot, oaa, oto, iit, atc, atp, itp, aoa, iot, oat, ati, ast, tio, sit, aia, asa, toa, ctt, trt, saa, aso, tas, cat, wat, tti, ttp, aao, aas, rot, tai, ate, tpt, awa, ote, oti, aai, pit, rtt, tsi, tft, cit, otm, iia, tra, twa, ias, tet, pat, sta, tdo, atr, bat, aco, otr, bot, atm, awt, tea, tma, twt, too, tte, tmo, tpi, dot, tba, act, tci, aft, aac, caa, ite, aca, tsw, apo, tac, ito, tfo, ttw, iti, atw, btt, tii, tmt, oit, apa, otf, asi, tdt, ttm, tbt, aap, bta, itm, eit, tlo, tcw, aar, ttr, atb, tno, soa, tfa, sia, oia, eat, tda, wta, tss, aii, art, tap, fot, waa, tpw, atf, iai, aea, oas, oao, paa, rat, tnt, tbo, ftt, ooa, otb, rit, atd, itf, itr, aaw, dit, cwt, coa, iac, tps, fta, taw, fat, rta, wtt, otd, ath, aae, tha, baa, ioa, poa, tae, cta, ist, ptt
These trigrams appeared 1880623 times, making up 20.6% of the total. The 969 most frequent trigrams made up 50% of the occurrences, with the other 50% comprising of 15225 trigrams.
Overall, the disparity between the frequency of the most-seen trigrams and the frequency of the least-seen trigrams is pretty huge, which serves to demonstrate just how non-uniform the sequences of first letters of words are.