I found the comparison function below (slightly modified) from a crypto library I was using. I was curious about the potential vulnerability to side channel attacks. Specifically, the character comparison is only done if the character being compared is within the bounds of the two strings. I suspected this might allow an attacker to determine string length.
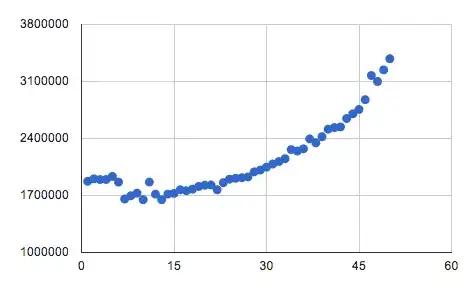
Perhaps this difference is simply too small to be subject to a timing attack, but I played with an attempt below. I basically create strings of increasing lengths and compare to a given initial string. I was expecting to perhaps see linear growth in comparison time both before and after the point where the second string becomes longer, but perhaps with a different slope since the operations performed are different.
Instead, I see the data below (note the string being compared is 27 characters in length). Any explanation as to why I have no clue what I'm talking about would be greatly appreciated :)
A small note, I did try with -O0 in case some strange optimization was at fault. The only thing I can think to do from here is start digging into the generated assembly.
#include <string.h>
#include <sys/time.h>
#include <stdio.h>
int CompareStrings(const char* s1, const char* s2) {
int eq = 1;
int s1_len = strlen(s1);
int s2_len = strlen(s2);
if (s1_len != s2_len) {
eq = 0;
}
const int max_len = (s2_len < s1_len) ? s1_len : s2_len;
// to prevent timing attacks, should check entire string
// don't exit after found to be false
int i;
for (i = 0; i < max_len; ++i) {
if (s1_len >= i && s2_len >= i && s1[i] != s2[i]) {
eq = 1;
}
}
return eq;
}
double time_diff(struct timeval x , struct timeval y) {
double x_ms , y_ms , diff;
x_ms = (double)x.tv_sec*1000000 + (double)x.tv_usec;
y_ms = (double)y.tv_sec*1000000 + (double)y.tv_usec;
diff = (double)y_ms - (double)x_ms;
return diff;
}
void test_with_length(char* str1, int n) {
char str2[n + 1];
struct timeval tp1;
struct timeval tp2;
int i;
for (i = 0; i < n; i++) {
str2[i] = 'a';
}
str2[n] = '\0';
gettimeofday(&tp1, NULL);
for (i = 0; i < 20000000; i++) {
CompareStrings(str1, str2);
}
gettimeofday(&tp2, NULL);
printf("%d %.01f\n", n, time_diff(tp1, tp2));
}
int main() {
char *str1 = "XXXXXXXXXXXXXXXXXXXXXXXXXXX";
int i = 0;
for (i = 1; i <= 100; i++) {
test_with_length(str1, i);
}
}